搭建ELK日志收集分析系统
日志主要包含系统日志、应用日志和安全日志。运维和开发人员通过日志可以了解服务器、程序运行情况,发现错误及检查错误发生原因。一个可靠、安全、可扩展的日志收集分析解决方案在程序或系统异常时能够让一切都变得轻松起来。
对比了ELK几种搭建模式:
- filebeat->elasticsearch->kibana
- filebeat->logstash->kafaka&zookeeper->logstash->elasticsearch->kibana
- filebeat->kafaka&zookeeper->logstash->elasticsearch->kibana
架构
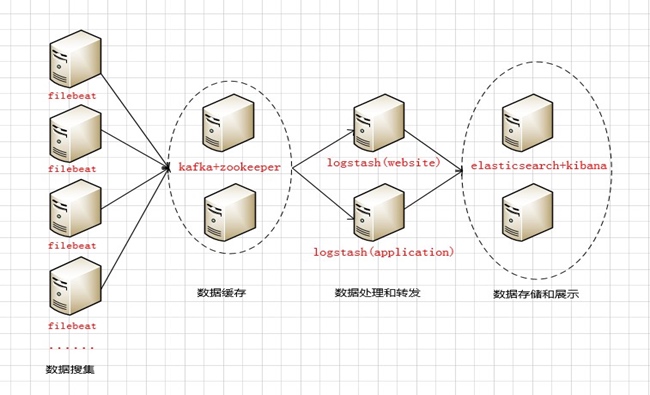
从左到右分别为:
1)、数据采集层,将采集到的日志分别发送到kafka broker的集群队列上去
2)、数据缓存层,将采集到的日志临时转存到本地的kafka broker集群中(相当于队列的生产者)
3)、数据处理转发层,logstash实时去kafka broker集群拉去日志,在经过本地logstash后进行日志分析处理,然后转发到后端elasticsearch(相当于队列的消费者)
4)、数据存储展示层,elasticsearch将收集到的日志进行本地存储,然后通过kibana展示出来;由于elasticsearch采用集群的方式,前端通过nginx在反向代理kibana的访问地址,使用户访问入口只有一个
资源列表
| 服务器名称 | IP地址 | 角色 | 功能 |
|---|---|---|---|
| kz1 | 172.31.2.2 | kafka+zookeeper | kafka broker节点1 |
| kz2 | 172.31.2.3 | kafka+zookeeper | kafka broker节点2 |
| logstash-web | 172.31.2.4 | logstash | 处理转发web相关日志 |
| logstash-app | 172.31.2.5 | logstash | 处理转发app相关日志 |
| es-node1 | 172.31.2.6 | elasticsearch+kibana | 数据存储展示 |
| es-node2 | 172.31.2.7 | elasticsearch+kibana | 数据存储展示 |
硬件配置
| 服务器类型 | 实例类型 | CPU | 内存 | Disk |
|---|---|---|---|---|
| Kafka broker集群 | r5.xlarge | 4 | 32 | 1T |
| Logstash | c5.2xlarge | 8 | 16 | 100G |
| Elasticsearch+kibana | r5.xlarge | 4 | 32 | 2T |
部署前的准备工作
分别在这6台服务器上进行设置
1)、主机名设置
$ sudo vim /etc/hosts
172.31.2.2 kz1
172.31.2.3 kz2
172.31.2.4 logstash-web
172.31.2.5 logstash-app
172.31.2.6 es-node1
172.31.2.7 es-node2
验证:在其中任何一台服务器上ping 主机名,能通,则代表设置生效
(备注:需要在aws上的ec2的安全策略上分别开启ICMP流量)
2)、系统优化
2.1)、打开最大文件描述符
$ sudo vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
* soft nproc 2048
* hard nproc 4096
验证:退出当前终端在重新登录,$ ulimit -n 显示65535,表示设置生效
2.2)、内核调整
$ sudo vim /etc/sysctl.conf
vm.max_map_count = 262144 # elasticsearch启动时所拥有的虚拟内存区域数量,过小,es会无法启动
vm.swappiness = 0 # 不使用虚拟内存
设置生效: $ sudo sysctl -p
3)、软件包准备
jdk-8u151-linux-x64.tar.gz
filebeat-5.5.2-linux-x86_64.tar.gz
kafka_2.12-2.0.0.tgz
zookeeper-3.4.13.tar.gz
logstash-5.5.2.tar.gz
elasticsearch-5.5.2.tar.gz
kibana-5.5.2-linux-x86_64.tar.gz
备注:软件包存放位置 /usr/local/programs/src
4)、安装配置supervisor
$ sudo mkdir /usr/local/programs/supervisor -pv
$ sudo apt-get update
$ sudo apt-get install python-pip –y
$ sudo locale-gen zh_CN.UTF-8 en_US.UTF-8
$ sudo pip install supervisor
$ sudo su
$ /usr/local/bin/echo_supervisord_conf > /usr/local/programs/supervisor/supervisord.conf
supervisor配置文件修改调整
$ sudo vim supervisord.conf
[inet_http_server] # 去掉前面的注释
port=127.0.0.1:9001 # 去掉前面的注释,开启supervisor端口监听
[supervisord]
logfile=/usr/local/programs/supervisor/supervisord.log # 设置supervisor的日志文件路径
environment=JAVA_HOME="/usr/local/programs/jdk" # 设置java环境变量
[include]
files = conf.d/*.conf # supervisor包含的配置文件,此处使用相对路径
备注:需创建服务配置目录:$ sudo mkdir /usr/local/programs/supervisor/conf.d
部署过程
1)、jdk安装
以下操作分别在这6台服务器上安装
1.1)、解压安装包并指定目录
$ sudo tar -zxvf jdk-8u151-linux-x64.tar.gz -C /usr/local/programs
$ cd /usr/local/programs && sudo mv jdk1.8.0_151 jdk
1.2)、设置全局环境变量
编辑/etc/profile在文件在最后添加如下内容:
# set java environment
export JAVA_HOME=/usr/local/programs/jdk
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
1.3)、使Jdk环境变量配置生效
$ source /etc/profile
1.4)、验证
$ echo $JAVA_HOME
2)、zookeeper安装配置
以下操作步骤在kz1和kz2服务器上进行安装部署
2.1)、解压软件包到指定目录
$ sudo tar -zxvf zookeeper-3.4.13.tar.gz -C /usr/local/programs
$ cd /usr/local/programs && sudo mv zookeeper-3.4.13 zookeeper
2.2)、编辑zookeeper配置文件
$ cd /usr/local/programs/zookeeper/conf
$ cp -a zoo_sample.cfg zoo.cfg
$ sudo vim zoo.cfg
完整配置文件如下:
tickTime=2000
# zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每个tickTime时间会发送一次心跳
initLimit=10
# 集群中Zookeeper的leader和Follower服务器之间初始化连接时最长能忍受多少个心跳时间间隔数,总的时间长度为5*2000-10秒,当超过这个长度时,Zookeeper服务器还没有收到客户端的返回信息,表明客户端连接失败
syncLimit=5
# zookeeper集群中Leader与Follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,此时为5*2000=10秒
dataDir=/usr/local/programs/zookeeper/data
# 设置zookeeper保存数据的目录,默认zookeeper将写数据的日志文件也保存在这个目录里
dataLogDir=/usr/local/programs/zookeeper/logs
# 设置Zookeeper保存日志的目录
clientPort=2181
# 客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接受客户端的访问请求
server.1=172.31.2.2:2888:3888
server.2=172.31.2.3:2888:3888
# 此选项为集群配置选项:server.1:代表是第几号服务器;172.31.2.2:代表这个服务器的IP地址;2888:表示这个服务器与集群中的Leader服务器交换信息的端口;3888:表示万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口
备注:将此配置文件同步至kafka broker集群中的另外两台服务器上
2.3)、创建myid文件
在172.31.2.2(kz1)服务器上执行:
$ echo 1 > /usr/local/programs/zookeeper/data/myid
在172.31.2.3(kz2)服务器上执行:
echo 2 > /usr/local/programs/zookeeper/data/myid
备注:此时的myid文件必须创建在zoo.cfg配置文件里面的dataDir指定的目录内
myid文件说明:zookeeper启动时会读取这个文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断自己到底是哪个server
2.4)、启动zookeeper服务
分别在172.31.2.2、172.31.2.3这两台服务器上执行如下命令:
$ sudo /usr/local/programs/zookeeper/bin/zkServer.sh start
备注:zookeeper默认是以后台方式启动
前台启动方式为:$ sudo /usr/local/programs/zookeeper/bin/zkServer.sh start-foreground
2.5)、查看zookeeper集群状态
分别在172.31.2.2、172.31.2.3这两台服务器上执行如下命令:
# 172.31.2.2
/usr/local/programs/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/programs/zookeeper/bin/../conf/zoo.cfg
Mode: follower
#172.31.2.3
/usr/local/programs/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/programs/zookeeper/bin/../conf/zoo.cfg
Mode: leader
Mode: follower
3)、kafka集群安装配置
3.1)、解压安装到指定目录
$ sudo tar -zxvf kafka_2.12-2.0.0.tgz -C /usr/local/programs/kafka
3.2)、Kafka jvm内存调整
$ sudo vim /usr/local/programs/kafka/bin/kafka-server-start.sh
修改如下地方:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G" # 此处设置为内存的一半
fi
3.3)、修改配置文件
$ sudo vim /usr/local/programs/kafka/config/server.properties
完整配置文件如下:
# see kafka.server.KafkaConfig for additional details and defaults
############################### Server Basics #########################################
broker.id=1 # 每个broker在集群中的唯一标识,要求为正数
port=9092 # kafka监听端口,不配置默认为9092
host.name=kz1 # broker的主机地址或主机名(重要)
############################### Socket Server Settings #################################
num.network.threads=4 # 接收消息的线程数量,接收线程会将接收到的消息放在内存中,然后再从内存中写入磁盘(建议调整为CPU的核心数,根据实际情况调整)
num.io.threads=8 # 消息从内存中写入磁盘的时候使用的线程数量,用来处理磁盘IO的线程数量(建议调整为CPU核心数的2倍)
socket.send.buffer.bytes=102400 # 发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 # 接收套接字的缓冲区大小
socket.request.max.bytes=104857600 # 请求套接字的缓冲区大小
############################### Log Basics ###########################################
log.dirs=/usr/local/programs/kafka/logs # Kafka运行日志存放的路径
num.partitions=1 # topic在当前broker上的分片个数
num.recovery.threads.per.data.dir=1 # 设置恢复和清理data下数据的线程数量(segment文件默认会被保留7天的时间,超时的话就会被清理,清理需要线程来执行)
############################## Log Retention Policy #####################################
log.retention.hours=168 # segment文件保留最长时间,默认保留7天(168小时),超时将被清除
log.segment.bytes=1073741824 # 日志文件每个segment的大小,默认为1G
log.retention.check.interval.ms=300000 # 周期性检查segment文件大小的时间(单位是毫秒)
############################### Zookeeper ###########################################
zookeeper.connect=172.31.2.2:2181,172.31.2.3:2181
# zookeeper集群的地址,可以是多个,多个之间用逗号隔开
zookeeper.connection.timeout.ms=6000 # zookeeper的连接超时时间
############################### Group Coordinator Settings ###########################
group.initial.rebalance.delay.ms=0 # 新版本添加的参数;这个参数的主要效果就是让coordinator推迟空消费组接收到成员加入请求后本应立即开启的rebalance,在实际使用时,假设你预估你的所有consumer组成员加入需要在10s内完成,那么你就可以设置该参数=10000
将配置文件同步到kz2服务器上:
$ scp server.properties [email protected]:/usr/local/programs/kafka/config
修改配置文件:
broker.id=2
host.name=kz2
3.4)、启动kafka服务
前台方式启动:
$ sudo /usr/local/programs/kafka/bin/kafka-server-start.sh /usr/local/programs/kafka/config/server.properties
后台启动方式:
$ sudo /usr/local/programs/kafka/bin/kafka-server-start.sh --daemon /usr/local/programs/kafka/config/server.properties
3.5)、Kafka消息监控-KafkaOffsetMonitor
简介:
1)、这个应用程序用来实时监控Kafka服务的Consumer以及它们所在的Partition中的Offset,我们可以浏览当前的消费者组,并且每个Topic的所有Partition的消费情况都可以观看的一清二楚
2)、它让我们很直观的知道,每个Partition的Message是否消费掉,有没有阻塞等等
3)、这个Web管理平台保留的Partition、Offset和它的Consumer的相关历史数据,我们可以通过浏览Web管理的相关模块,清楚的知道最近一段时间的消费情况
下载地址:https://github.com/quantifind/KafkaOffsetMonitor/releases/tag/v0.2.1
$ cd /usr/local/programs/
$ sudo mkdir kafka_monitor
$ sudo vim monitor_start.sh
#! /bin/bash
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \ com.quantifind.kafka.offsetapp.OffsetGetterWeb \ --zk h1:2181 \ --port 8089 \ --refresh 10.seconds \ --retain 1.days
服务启动:$ cd /usr/local/programs/kafka_monitor && $ bash monitor_start.sh
4)、logstash安装配置
4.1)、解压安装包到指定目录
$ sudo tar -zxvf logstash-5.5.2.tar.gz -C /usr/local/programs/logstash
4.2)、jvm内存优化调整
$ sudo vim /usr/local/programs/logstash/config/jvm.optons -Xms8g
-Xmx8g # 建议设置为内存的一半(根据实际情况进行调整)
4.3)、修改配置文件
$ sudo vim /usr/local/programs/logstash/config/logstash.yml
path.data: /usr/local/programs/logstash/data
pipeline.workers: 8 # CPU核心数
pipeline.output.workers: 4 # 这里相当于output elasticsearch里面的workers数量
pipeline.batch.size: 1000 # 根据qps,压力情况等调整
pipeline.batch.delay: 5
path.config: /usr/local/programs/logstash/config/conf.d # logstash的配置文件存放位置
path.logs: /usr/local/programs/logstash/logs # logstash的日志文件
4.4)、启动logstash
logstash前台启动方式:
$ sudo /usr/local/programs/logstash/bin/logstash -f /usr/local/programs/logstash/conf/oc-logstash-kafka.conf
logstash后台启动方式:
$ sudo nohup /usr/local/programs/logstash/bin/logstash -f /usr/local/programs/logstash/conf/oc-logstash-kafka.conf &
4.5)、Logstash安装geoip插件
$ cd /usr/local/programs/logstash
$ sudo ./bin/logstash-plugin install logstash-filter-geoip
验证插件是否安装:$ sudo ./bin/logstash-plugin list | grep geoip
Logstash安装x-pack插件(插件按照后面elasticsearch的x-pack插件破解方式进行破解)
$ cd /usr/local/programs/logstash
$ sudo ./bin/logstash-plugin install x-pack
$ sudo vim logstash.yml
xpack.monitoring.elasticsearch.username: logstash_system
xpack.monitoring.elasticsearch.password: logstashpassword
5)、Elasticsearch集群安装配置
5.1)、解压软件包至指定目录
$ sudo tar -zxvf elasticsearch-5.5.2.tar.gz -C /usr/local/programs/elasticsearch
5.2)、JVM配置
由于elasticsearch是Java开发的,所以可以通过修改/usr/local/programs/elasticsearch/jvm.options配置文件来设定JVM的相关设定
$ sudo vim /usr/local/programs/elasticsearch/jvm.options -Xms4g
-Xmx4g # 建议设置为内存的一半(根据实际情况调整)
调整elasticsearch GC方法(此参数调整特别注意,容易导致elasticsearch无法启动)
GC configuration
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
修改为:
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
5.3)、修改配置文件
$ sudo vim elasticsearch.yml
cluster.name: elasticsearch-application # elasticsearch集群名称
node.name: node-1 # node节点名称
node.master: true # 表示节点是否具有成为主节点的资格
node.data: true # 表示节点是否存储数据
node.attr.rack: r1 # 将自定义的属性添加到节点·
path.data: /usr/local/programs/elasticsearch/data # ES数据存放位置
path.logs: /usr/local/programs/elasticsearch/logs # ES 日志存放位置
bootstrap.memory_lock: true # 锁定物理内存地址, 防止elasticsearch内存被交换出去
# 备注
# Make sure that the heap size is set to about half the memory available on the system and that the owner of the process is allowed to use this limit.
# 确保ES_HEAP_SIZE参数设置为系统可用内存的一半左右
# Elasticsearch performs poorly when the system is swapping the memory
# 当系统进行内存交换的时候, es的性能很差
network.host: 192.168.2.6 # 为es设置IP绑定
http.port: 9200 # 为es设置自定义端口,默认是9200
discovery.zen.ping.unicast.hosts: ["172.31.2.6:9300", "172.31.2.7:9300"]
# 当启动新节点时, 通过ip列表进行节点发现, 组件集群
discovery.zen.minimum_master_nodes: 3 # 防止集群脑裂现象(集群总节点数量/2+1)
gateway.recover_after_nodes: 3 # 一个集群中的N各节点启动后, 才允许进行数据恢复处理
# x-pack和es-head插件配置参数
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true (es登录通过x-pack插件验证)
xpack.security.transport.ssl.enabled: true
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*,.security,.security-6
将elasticsearch的配置文件同步到另外一台服务器(172.31.2.7)
修改配置文件:
node.name: node-2 # node节点名称
network.host: 192.168.2.7 # es设置IP绑定
5.4)、启动elasticsearch服务
Elasticsearch默认前台启动:
$ sudo /usr/local/programs/elasticsearch/bin/elasticsearch
5.5)、elasticsearch head插件安装
5.5.1)、下载elasticsearch-head插件
$ cd /usr/local/programs && sudo git clone https://github.com/mobz/elasticsearch-head.git
5.5.2)、elasticsearch-head配置文件修改
$ cd elasticsearch-head
$ sudo vim Gruntfile.js
connect: {
server: {
options: {
port: 9100,
hostname: '*',
base: '.',
keepalive: true
}
}
}
$ sudo vim _site/app.js
修改如下地方:
this.base_uri = this.config.base_uri || this.prefs.get(“app-base_uri”) || “http://192.168.2.6:9200”;
Enable CORS in elasticsearch
1)、add http.cors.enabled: true
2)、you must also set http.cors.allow-origin because no origin allowed by default. http.cors.allow-origin: “*” is valid value, however it’s considered as a security risk as your cluster is open to cross origin from anywhere
$ sudo apt-get update && $ sudo apt-get install nodejs
$ sudo apt-get install npm
$ sudo ln -s /usr/bin/nodejs /usr/bin/node
5.5.3)、elasticsearch-head插件服务启动方式
$ cd /usr/local/programs/elasticsearch/elasticsearch-head
$ npm install
$ npm run start
此时elasticsearch head插件安装完成
5.6)、elasticsearch x-pack插件安装
$ cd /usr/local/programs/elasticsearch
$ sudo bin/elasticsearch-plugin install x-pack
安装完成后,再次登录 http://xxx.xxx.xxx.xxx:9200时,提示需要输入密码
默认账户密码:elastic,changeme
5.7)、elasticsearch x-pack插件破解
反编译class文件:
在elasticsearch安装目录plugins/x-pack/找到x-pack-5.5.2.jar文件
新建测试目录test
$ cd /usr/local/programs/elasticsearch/plugins/x-pack/ && sudo mkdir test
剪切x-pack-5.5.2.jar文件到测试目录test文件夹里面
$ sudo mv /usr/local/programs/elasticsearch/plugins/x-pack/x-pack-5.5.2.jar test/
切换到test目录,解压jar包
$ cd /usr/local/programs/elasticsearch/plugins/x-pack/test && jar –xvf x-pack-5.5.2.jar
$ sudo rm -rf /usr/local/programs/elasticsearch/plugins/x-pack/test/x-pack-5.5.2.jar
找到文件org.elasticsearch/license/LicenseVerifier.class,并用Luyten反编译,
新建文件LicenseVerifier.java,内容如下:
package org.elasticsearch.license;
import java.nio.*;
import java.util.*;
import java.security.*;
import org.elasticsearch.common.xcontent.*;
import org.apache.lucene.util.*;
import org.elasticsearch.common.io.*;
import java.io.*;
public class LicenseVerifier
{
public static boolean verifyLicense(final License license, final byte[] encryptedPublicKeyData) {
return true;
}
public static boolean verifyLicense(final License license) {
return true;
}
}
在当前系统上的任意目录上重新编译LicenseVerifier.java文件
$ javac -cp "/usr/local/programs/elasticsearch/lib/elasticsearch-5.2.2.jar:/usr/local/programs/elasticsearch/lib/lucene-core-6.0.1.jar:/usr/local/programs/elasticsearch/plugins/x-pack/x-pack-5.5.2.jar" LicenseVerifier.java
此时会生成一个LicenseVerifier.class的文件
替换原来的class文件
$ sudo cp LicenseVerifier.class /usr/local/programs/elasticsearch/plugins/x-pack/test/org/elasticsearch/license/
重新打包jar包
$ cd /usr/local/programs/elasticsearch/plugins/x-pack/test && jar -cvf x-pack-5.5.2.jar ./*
覆盖原来的x-pack的jar包
$ sudo mv /usr/local/programs/elasticsearch/plugins/x-pack/test/x-pack-5.5.2.jar /usr/local/programs/elasticsearch/plugins/x-pack
获取license文件
获取地址:https://license.elastic.co/registration
将下载下来的license文件重命名为license.json
修改文件内容的两处:
"type": "platinum",
"expiry_date_in_millis": 2524579200999,
在更新license文件之前,需要修改elasticsearch配置文件elasticsearch.yml
xpack.security.enabled: false
导入修改好的license文件
$ curl -XPUT -u elastic 'http://192.168.2.6:9200/_xpack/license?acknowledge=true' -H "Content-Type: application/json" -d @license.json
生效之后,再开启security,并开启SSL\TLS:
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
最后重启elasticsearch:
查看License状态:
$ curl -XGET -u elastic http://192.168.2.6:9200/_license
6)、Kibana安装配置
6.1)、解压软件包至指定目录
$ sudo tar -zxvf kibana-5.5.2-linux-x86_64.tar.gz -C /usr/local/programs/kibana
6.2)、修改配置文件
server.port: 5601
server.host: "0.0.0.0"
server.name: "elk-es1"
elasticsearch.url: http://172.31.2.6:9200
kibana.index: ".kibana"
elasticsearch.username: "kibana"
elasticsearch.password: "changeme"
6.3)、kibana x-pack插件安装
$ cd /usr/local/programs/kibana
$ bin/kibana-plugin install x-pack
# Update Kibana to use the new password for the built-in kibana user, which you set up along with the other built-in users when you installed X-Pack on Elasticsearch. You must configure the elasticsearch.password setting in the kibana.yml configuration file with the new password for the kibana user
elasticsearch.username: "kibana"
elasticsearch.password: "changeme"
备注: kibana安装选择在从节点的进行安装就可以了,主节点上无需安装!
####################################################################################
### 7)、Elasticsearch+logstash+kibana5.5密码重置
https://www.elastic.co/guide/en/x-pack/5.5/setting-up-authentication.html
elastic:A built-in superuser. See Built-in Roles.
kibana:The user Kibana uses to connect and communicate with Elasticsearch.
logstash_system:The user Logstash uses when storing monitoring information in Elasticsearch.
You must reset the default passwords for all built-in users, and then disable default password support. You can update passwords from the Management > Users UI in Kibana or with the Reset Password API:
PUT _xpack/security/user/elastic/_password
{
"password": "elasticpassword"
}
PUT _xpack/security/user/kibana/_password
{
"password": "kibanapassword"
}
PUT _xpack/security/user/logstash_system/_password
{
"password": "logstashpassword"
}
备注: 当密码被更改后,请将kibana配置文件中连接elasticsearch的密码也进行更换
服务安装目录以及配置文件位置说明
kafka安装目录: /usr/local/programs/kafka
kafka配置文件: /usr/local/programs/kafka/config/server.properties
kafka jvm配置文件: /usr/local/programs/kafka/bin/kafka-server-start.sh
kafka monitor安装目录: /usr/local/programs/kafka_monitor
zookeeper安装目录: /usr/local/programs/zookeeper
zookeeper配置文件: /usr/local/programs/zookeeper/conf/zoo.cfg
logstash安装目录: /usr/local/programs/logstash
logstash配置文件: /usr/local/programs/logstash/config/logstash.yml
logstash生产配置文件目录文件存放位置: /usr/local/programs/logstash/config/conf.d #里面文件为.yml结尾
logstash jvm配置文件: /usr/local/programs/logstash/config/jvm.options
elasticsearch安装目录: /usr/local/programs/elasticsearch
elasticsearch配置文件:/usr/local/programs/elasticsearch/config/elasticsearch.yml
elasticsearch jvm配置文件: /usr/local/programs/elasticsearch/config/jvm.options
kibana安装目录: /usr/local/programs/kibana
kibana 配置文件: /usr/local/programs/kibana/config/kibana.yml
备注:
所有elk服务启动都采用supervisor进程管理的方式维护
ELK中相关服务端口说明
9092: kafka监听的端口
2181: zookeeper提供给client连接的端口
2888: zookeeper集群内部通讯使用端口(Leader监听此端口),意思是此端口不在集群哪台服务器上监听,就是Leader
3888: zookeeper选举Leader使用的端口
5044: logstash监听端口
5601:kibana监听访问端口
9200:elasticsearch监听访问端口
9300:elasticsearch集群内部通讯端口
ELK集群架构常用维护命令
1)、Kafka常用操作命令
1、创建kafka topic:
$ sudo bin/kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --create --topic my-topic --replication-factor 2 --partitions 8
备注:partitions指定topic分区数,replication-factor指定topic每个分区的副本数
partitions分区数:控制topic将分片成多少个log;可以显示指定,如果不指定则会使用broker(server.properties)中的num.partitions配置的数量
replication-factor副本:replication-factor控制消息保存在几个broker(服务器)上,一般情况下等于broker的个数
如果没有在创建时显示指定或通过API向一个不存在的topic生产消息时会使用broker(server.properties)中的default.replication.factor配置的数量
For example, increase the number of partitions for a topic named “my-topic” to 16:
$ sudo bin/kafka-topics.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --alter --topic my-topic --partitions 16
2、Deleting a Topic:
For example, delete the topic named “my-topic”:
$ sudo bin/kafka-topics.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --delete --topic my-topic
3、Listing All Topics in a Cluster
$ sudo bin/kafka-topics.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --list
4、Describing Topic Details
$ sudo bin/kafka-topics.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --describe --topic my-topic
5、分区监控指标(查找有问题的分区)
There are two filters used to find partitions that have problems. The –under-replicated-partitions argument
will show all partitions where one or more of the replicas for the partition are not in-sync with the leader. The –unavailable-partitions argument shows all partitions without a leader. This is a more serious situation
that means that the partition is currently offline and unavailable for produce or consume clients.
$ sudo bin/kafka-topics.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 –describe –under-replicated-partitions
6、查看topic消费进度
这个会显示出consumer group的offset情况,必须参数为–group,不指定–topic,默认为所有topic
Displays the: Consumer Group,Topic,Partitions,Offset,logSize,Lag,Owner for the specified set of Topics and Consumer Group
$ sudo bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group pv
7、Describing Configuration Overrides
For example, show all configuration overrides for the topic named “my-topic”:
$ kafka-configs.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --describe --entity-type topics --entity-name my-topic
8、Removing Configuration Overrides
$ kafka-configs.sh --zookeeper 172.31.2.2:2181,172.31.2.3:2181 --alter --entity-type topics --entity-name my-topic --delete-config retention.ms
2)、Zookeeper常用操作命令
Zookeeper支持某些特定的四字命令字母与其的交互;它们大多是查询的命令,用来获取Zookeeper服务的当前状态及相关信息;用户在客户端可以通过telnet或nc向Zookeeper提交相应的命令
echo stat | nc localhost 2181 # 查看哪个节点被选择作为follower或者leader
echo ruok | nc localhost 2181 # 测试是否启动了该server,若回复imok表示已经启动
echo dump | nc localhost 2181 # 列出未经处理的会话和临时节点
echo kill | nc localhost 2181 # 关掉server
echo conf | nc localhost 2181 # 输出相关服务配置的详细信息
echo cons | nc localhost 2181 # 列出所有连接到服务器的客户端的完全的连接/会话的详细信息
echo envi | nc localhost 2181 # 输出关于服务环境的详细信息(区别于conf命令)
echo reqs | nc localhost 2181 # 列出未经处理的请求
echo wchs | nc localhost 2181 # 列出服务器watch的详细信息
echo wchc | nc localhost 2181 # 通过session列出服务器watch的详细信息,输出与watch相关的会话的列表
echo wchp | nc localhost 2181 # 通过路径列出服务器watch的详细信息;它输出一个与session相关的路径上
ZooKeeper命令行工具类似于Linux的shell环境,不过功能肯定不及shell,但是使用它我们可以简单的对ZooKeeper进行访问,数据创建,数据修改等操作
当启动ZooKeeper服务成功之后,输入下述命令,连接到ZooKeeper服务:
zkCli.sh -server zkserver: 2181
命令行工具的一些简单操作如下:
使用ls命令来查看当前ZooKeeper中所包含的内容
[zk: zkserverIP:2181(CONNECTED) 1] ls /
创建一个新的znode,使用create /zk myData;这个命令创建了一个新的znode节点“zk”以及与它关联的字符串
[zk: zkserverIP:2181(CONNECTED) 2] create /zk "myData"
我们运行get 命令来确认znode 是否包含我们所创建的字符串:
[zk: zkserverIP:2181(CONNECTED) 3] get /zk
下面我们通过set 命令来对zk 所关联的字符串进行设置:
[zk: zkserverIP:2181(CONNECTED) 4] set /zk "zsl"
下面我们将刚才创建的znode 删除:
[zk: zkserverIP:2181(CONNECTED) 5] delete /zk
3)、Elasticsearch常用操作命令
1、查看索引文件
$ curl -XGET "http://elastic:[email protected]:9200/_cat/indices?v"
2、打开或关闭指定的索引文件
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21/_open'
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21/_close'
3、检索索引文件是否存在
$ curl --head http://elastic:[email protected]:9200/logstash-oc-nginx-access-2018.06.01
4、删除指定的索引
$ curl -XDELETE http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21
使用通配符批量删除索引文件:
$ curl -XDELETE 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.*'
5、清空索引缓存
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21/_cache/clear'
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21, .monitoring-es-6-2018.05.22/_cache/clear'
6、刷新索引数据
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21/_refresh'
7、优化索引数据
$ curl -XPOST 'http://elastic:[email protected]:9200/.monitoring-es-6-2018.05.21/_optimize'
8、信息检索与结果过滤
在Elasticsearch中的RESTful接口方式中,完成信息检索功能的关键词是_search,通过POST的方式发送到
Elasticsearch,其后再跟“?q=查询词”等,其形式表现为:
http://ip address:port/index_name/type_name/_search?q=
可以以curl -XGET 'http://localhost:9200/_search?q=hello+world' 的方式完成简单的检索
输出结果带缩进:http://ip address:9200/index_file_name/type_name/_search?q=field_name:Hello & pretty=true
上述方法是可以在指定的索引文件index_file_name、指定的类型文件type_name中,在指定的字段field_name中,查找包含Hello字符串的结果集
(1)、查询指定索引和指定类型下的信息(指定一个index和一个type名)
$ curl -XGET 'elastic:[email protected]:9200/page/pages/_search?q=field_name: Hello&pretty=true'
(2)、查询指定索引下所有类型中的信息(指定一个index名,没指定type)
$ curl -XGET 'elastic:[email protected]:9200/page/_search?q=field_name:Hello&pretty=true'
(3)、查询所有索引中的信息(没指定index和type名)
$ curl -XGET 'elastic:[email protected]:9200/_search?q=field_name:Hello&pretty=true'
(4)、查询多个索引下所有类型中的信息(指定多个index名,没指定type名)
$ curl -XGET 'elastic:[email protected]:9200/page, whale/_search?q=field_name:Hello&pretty=true'
(5)、查询多个索引下多个类型中的信息(指定多个index名和多个type名)
$ curl -XGET 'elastic:[email protected]:9200/page, whale/pages, log/_search?q=field_name:Hello&pretty=true'
在索引过程中,可以控制结果的规模以及从哪个结果开始返回,在请求中可以设置相应的属性,其中:
from:该属性指定了从那个结果开始返回
size:该属性指定了查询的结果集中包含的最大文档数
基本查询:基本查询涉及term查询、terms查询、match查询、match_all查询、query_string查询、prefix查询、range查询、more_like_this查询等
9、elasticsearch集群查看:
$ curl -XGET -u elastic "http://172.31.2.6:9200/_cat/nodes?pretty"
访问地址
Kibana:http://x.x.x.x:5601
Elasticsearch: http://x.x.x.x:9200
Elasticsearch-head:http://x.x.x.x:9100/?auth_user=elastic&auth_password=changeme