Ubuntu16.04环境Jira和Confluence搭建
jira和confluence都是Atlassian公司产品。jira是项目与事务跟踪工具,可以完成项目执行管理、敏捷开发管理、体系流程管理、产品Bug跟踪、提案跟踪、需求管理、客户服务等工作。confluence是一个专业的企业知识管理与协同软件,可以用于构建企业wiki,通过它可以实现团队成员之间的协作和知识共享。
一、环境
前一篇讲了挖矿病毒的入侵,决定对那台服务器上相关服务拆分迁移。上面的jira和confluence共用jira账号体系,迁移时两者要注意安装顺序,最后确定的方案:
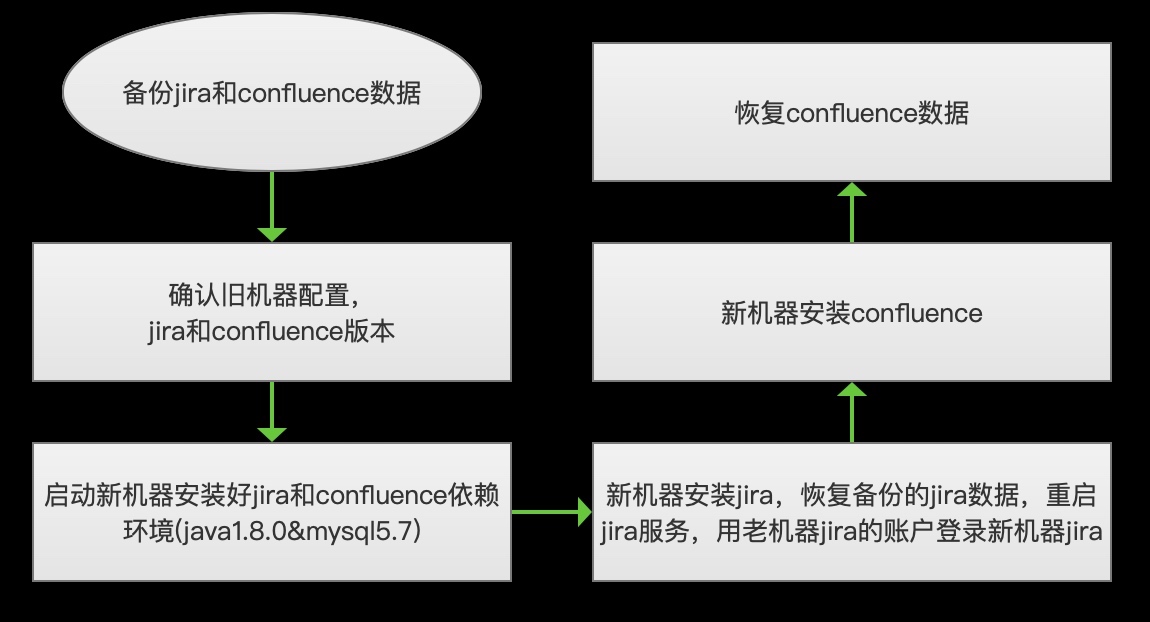
1.系统
系统:Ubuntu 16.04.5 LTS CPU:4核 内存:16G
上面机器配置最多可支持2000人,如果有更多人数需求,需升级配置。
2.Java环境
需安装jdk1.8以上版本
安装java
sudo apt install default-jre
查看java版本
ubuntu@ip-172-31-23-228:~$ java -version
openjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.16.04.1-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
3.Mysql
安装mysql5.7
sudo apt-get install mysql-server
根据提示一步步设置,完成后记住mysql默认账号root的密码。
二、Jira
1.下载文件
**a)**下载jira,选择和老机器上jira相同的版本
wget https://downloads.atlassian.com/software/jira/downloads/atlassian-jira-software-7.3.8-x64.bin
**b)**下载jira7.3.8破解文件
解压jira-lib-7.3.8.zip文件
ubuntu@ip-172-31-23-228:/usr/local/programs/src$ unzip jira7.3.8.zip
Archive: jira7.3.8.zip
inflating: jira7.3.8/atlassian-extras-3.2.jar
inflating: jira7.3.8/mysql-connector-java-5.1.39-bin.jar
2.配置jira数据库
登录mysql
mysql -uroot -p
执行下面的SQL
;创建数据库sql
CREATE DATABASE jira CHARACTER SET utf8 COLLATE utf8_bin;
;授权用户
GRANT ALL ON jira.* TO 'jira'@'localhost' IDENTIFIED BY 'jirapassword';
;刷新
FLUSH PRIVILEGES;
{% alert info %} 注意创建数据库时COLLATE需使用utf8_bin {% endalert %}
3.安装jira
给安装包添加可执行权限
chmod +x atlassian-jira-software-7.3.8-x64.bin
执行安装
./atlassian-jira-software-7.3.8-x64.bin
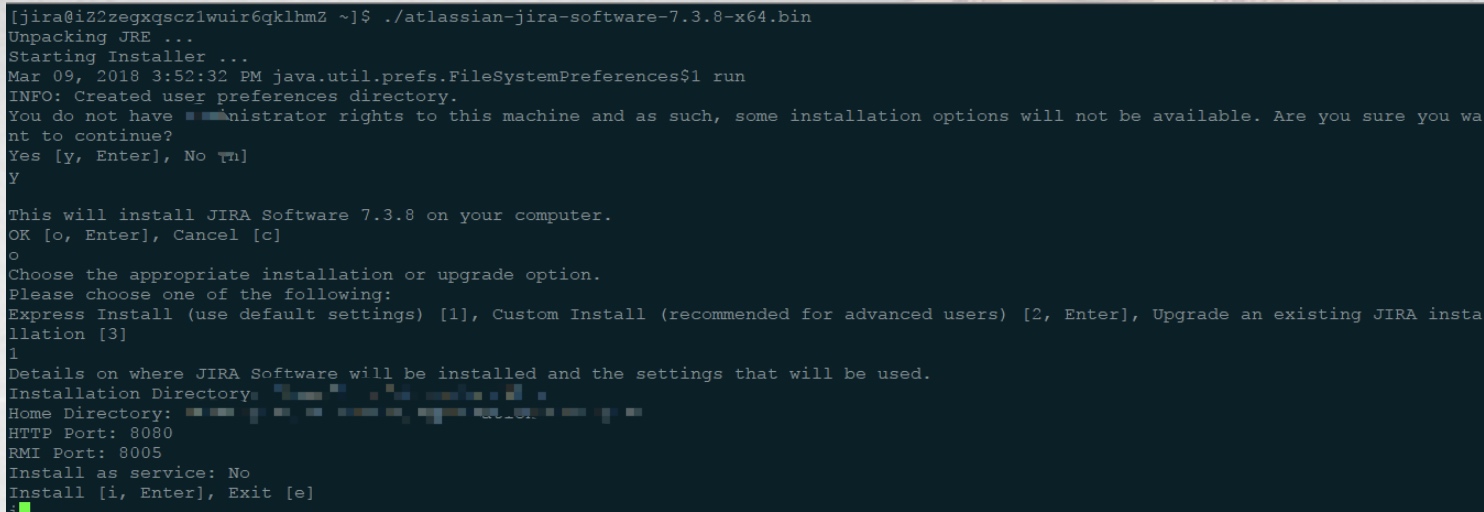
按照提示键入安装即可。 如果没有自定义目录,jira的程序和应用数据分表装到了两个目录:
应用:/opt/atlassian/jira
应用数据: /var/atlassian/application-data/jira
如果要修改jira默认端口,修改配置文件/opt/atlassian/jira/conf/server.xml
4.破解jira
先停掉jira服务
sudo /etc/init.d/jira stop
**a)**用破解文件atlassian-extras-3.2.jar替换/opt/atlassian/jira/atlassian-jira/WEB-INF/lib/atlassian-extras-3.2.jar文件
#先备份原文件
mv /opt/atlassian/jira/atlassian-jira/WEB-INF/lib/atlassian-extras-3.2.jar /tmp/atlassian-extras-3.2.jar
#替换文件
cp /破解文件目录/atlassian-extras-3.2.jar /opt/atlassian/jira/atlassian-jira/WEB-INF/lib/atlassian-extras-3.2.jar
**b)**确保jira可访问mysql,将mysql-connector-java-5.1.39-bin.jar拷贝/opt/atlassian/jira/atlassian-jira/WEB-INF/lib/路径下
cp /破解文件目录/mysql-connector-java-5.1.39-bin.jar /opt/atlassian/jira/atlassian-jira/WEB-INF/lib/mysql-connector-java-5.1.39-bin.jar
启动Jira服务, 默认端口8080
sudo /etc/init.d/jira start
按下图向导配置:
配置数据库
设置应用程序属性
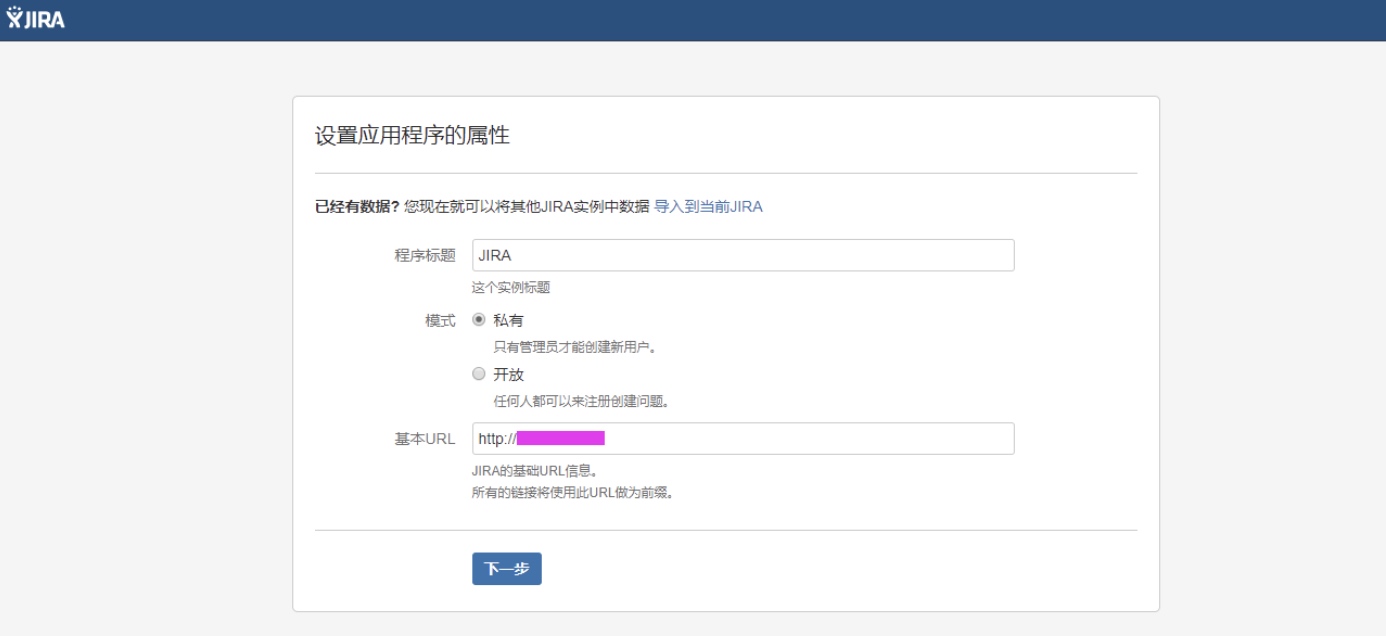
生成JIRA使用许可证
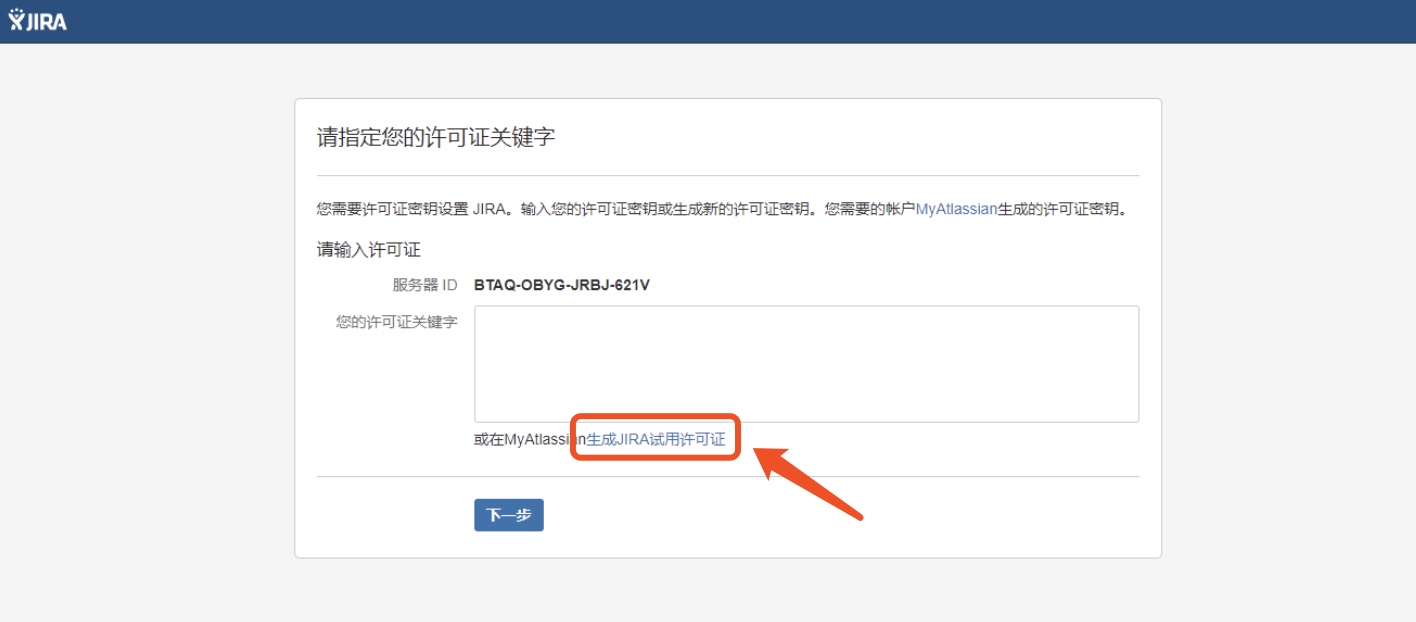
打开Atlassian官网获取许可证
继续下一步配置完邮件(也可先跳过),选择语言,至此Jira的安装和破解完成。
5.老机器jira数据备份,新机器jira数据恢复
**a)**管理员账号登录老机器jira
点击右上角的"系统"-“导入导出”-“备份系统”,Jira默认会打开自动备份的功能,备份路径为/var/atlassian/application-data/jira/export;入如果没有打开,也可以手动进行备份,如下,可以自定义备份的文件名。
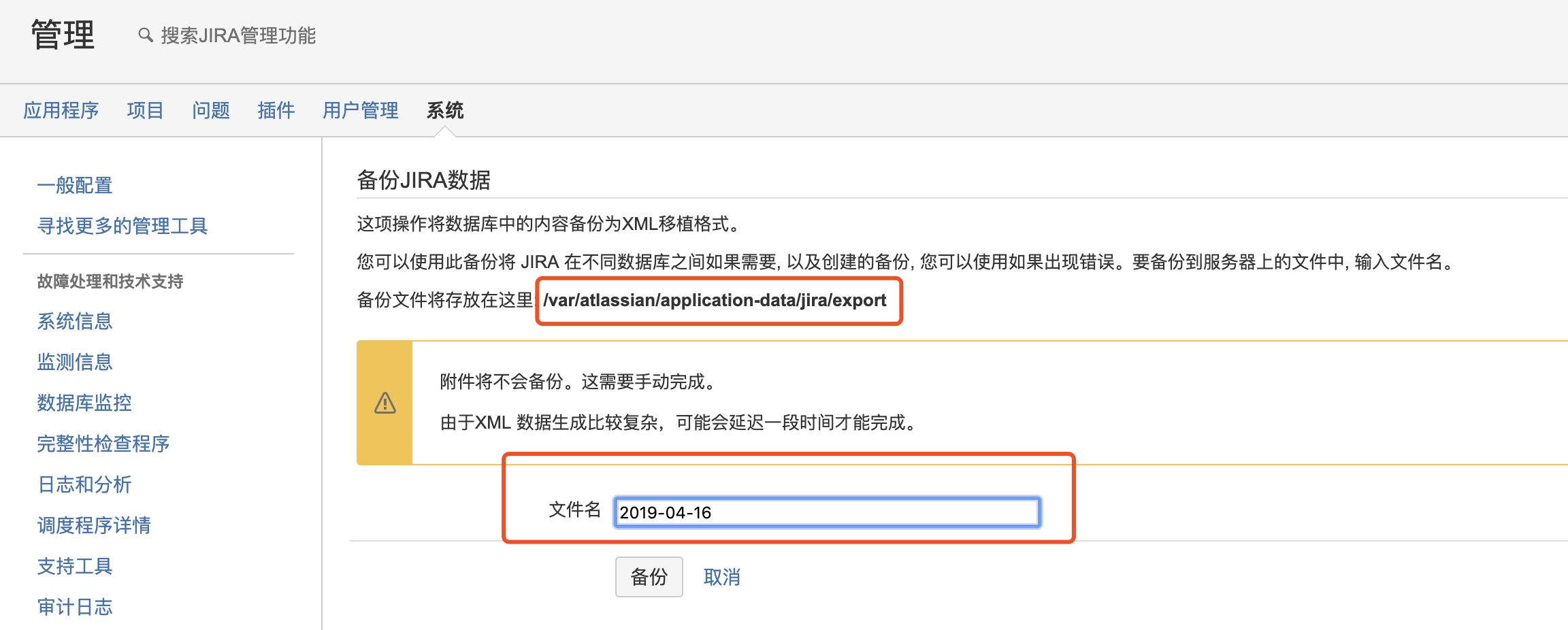
{% alert info %} 注意:这里的备份数据不包括附件。 jira附件都保存到服务器的/var/atlassian/application-data/jira/data/attachments路径下,这里的附件数据需要手动写脚本进行备份。点击右上角的"系统"-“高级”-“附件"就可以看到jira附件的设置。 {% endalert %}
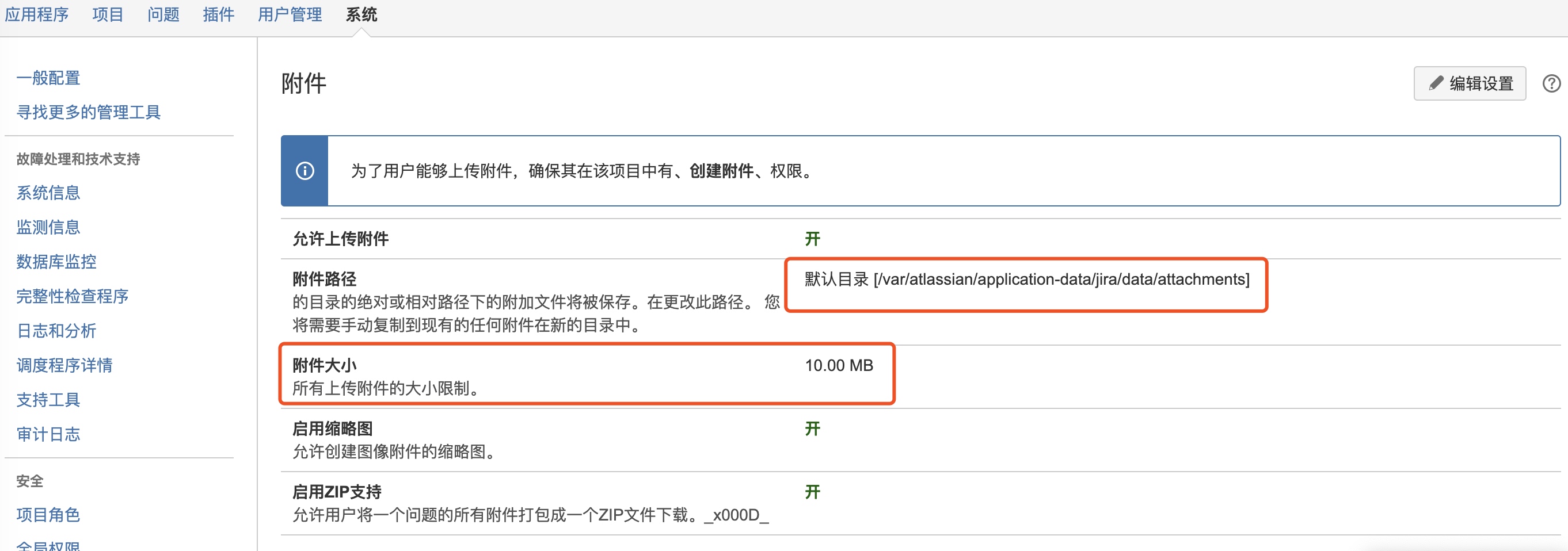
将jira的备份文件jira-backup.zip和attachments.zip文件拷贝到新机器。
**b)**管理员账号登录新机器jira
停止jira服务,将附件备份文件attachments.zip解压替换/var/atlassian/application-data/jira/data/attachments目录(可先备份)。
将备份文件jira-backup.zip拷贝到/var/atlassian/application-data/jira/import路径下。
启动jira服务,点击右上角的"系统”-“导入导出”-“恢复系统”,
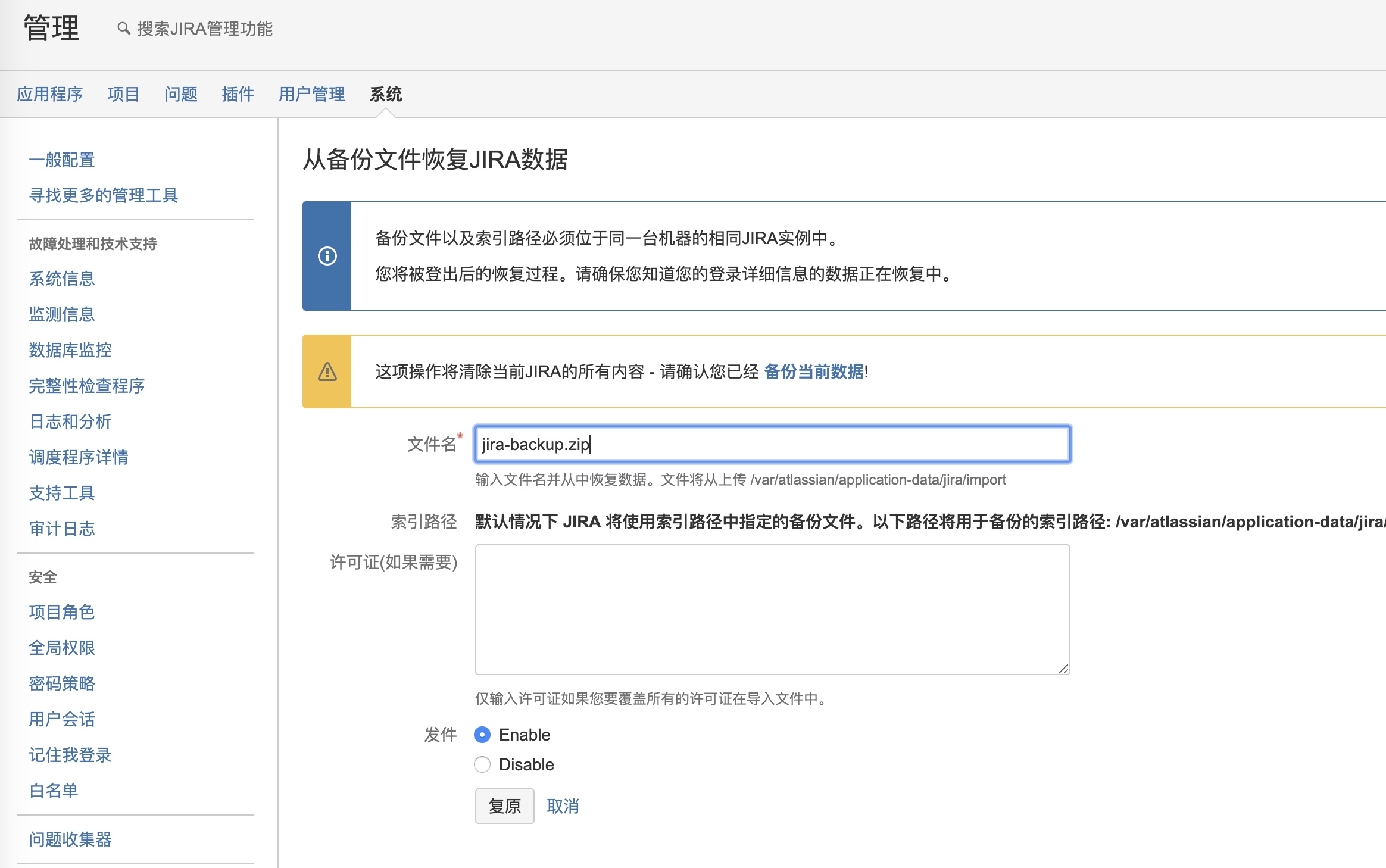
点击 [复原]开始恢复。
三、Confluence
老机器上是confluence6.3.1版本,这个版本的WebDAV和widgetconnector都存在漏洞,如果继续安装这个版本,恢复完数据估计很快又会沦为矿机。
针对上面两个漏洞官方在每个小版本里都发布了修复版,和6.3.1比较近的版本6.6.12就是一个修复了漏洞版本,所以决定下载并破解confluence6.6.12。
1.下载文件
**a)**下载confluence,选择和老机器上confluence相同的版本
**b)**下载mysql链接库和破解工具
解压unzip confluence-crack-tool.zip可以看到mysql链接库和破解工具confluence_keygen
2.配置confluence数据库
登录mysql
mysql -uroot -p
执行下面的SQL
;创建数据库sql
CREATE DATABASE confluence CHARACTER SET utf8 COLLATE utf8_bin;
;授权用户
GRANT ALL ON confluence.* TO 'confluence'@'localhost' IDENTIFIED BY 'confluencepassword';
;刷新
FLUSH PRIVILEGES;
{% alert info %} 注意创建数据库时COLLATE需使用utf8_bin {% endalert %}
3.安装confluence
给安装包添加可执行权限
chmod +x atlassian-confluence-6.6.12-x64.bin
执行安装
./atlassian-confluence-6.6.12-x64.bin
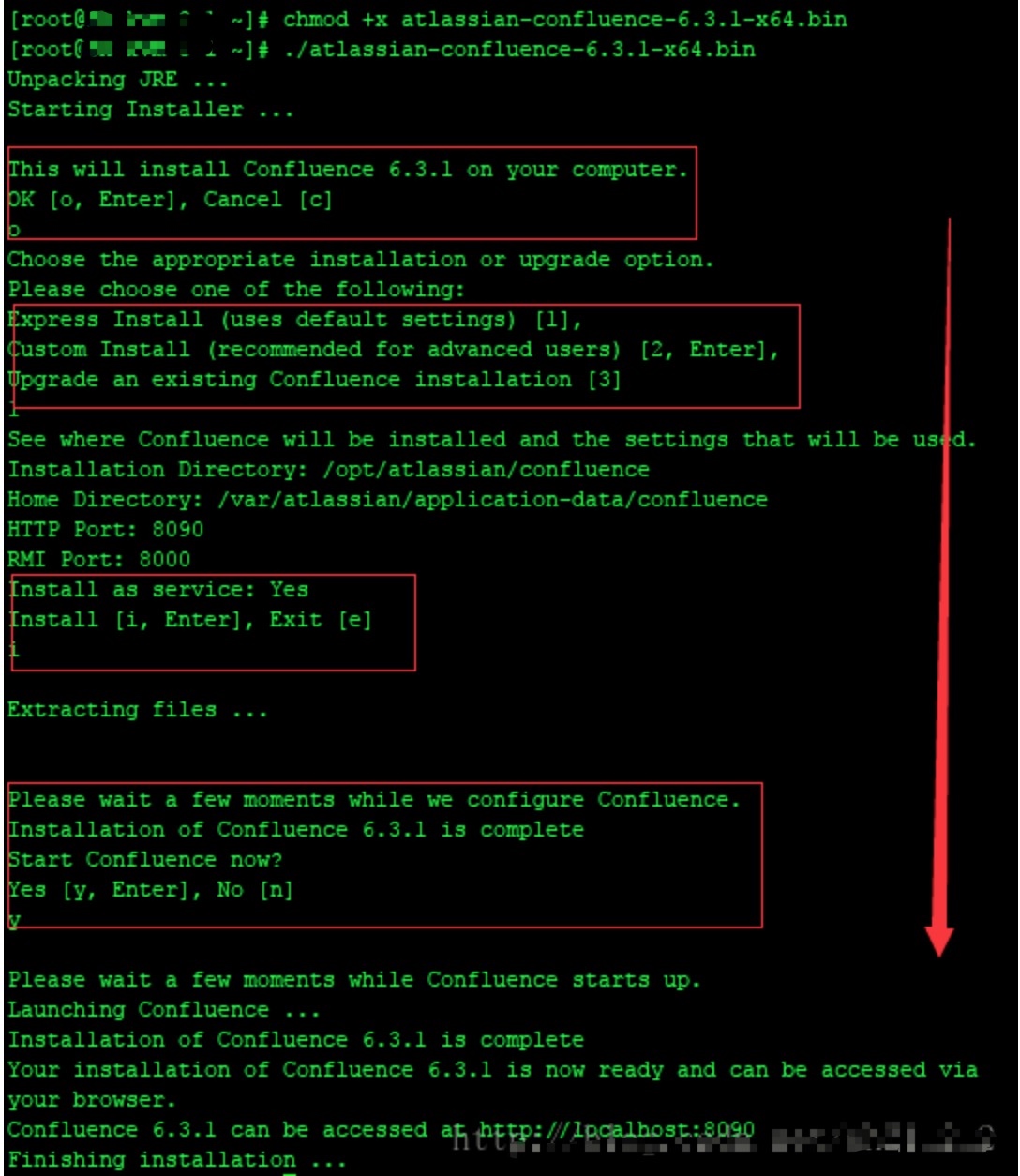
(截图用的6.3.1版本,仅参考)按照提示键入安装即可。(注意第一次确认是否继续,第二次选择安装方式(选1express安装),第三次是否启动服务) 如果没有自定义目录,jira的程序和应用数据分表装到了两个目录:
应用:/opt/atlassian/confluence
应用数据: /var/atlassian/application-data/confluence
默认监听的端口是8090,如果要修改confluence默认端口,修改配置文件/opt/atlassian/confluence/conf/server.xml
最后提示安装完成并启动了服务。
4.破解confluence
打开http://ip:8090(未配置完成前强烈建议用ip+port访问,不要用域名,重装过几次每次用域名访问配置到数据库那一步一定会报超时错误!用ip就不会),
先停掉confluence服务
sudo /etc/init.d/confluence stop
设置语言
选择产品
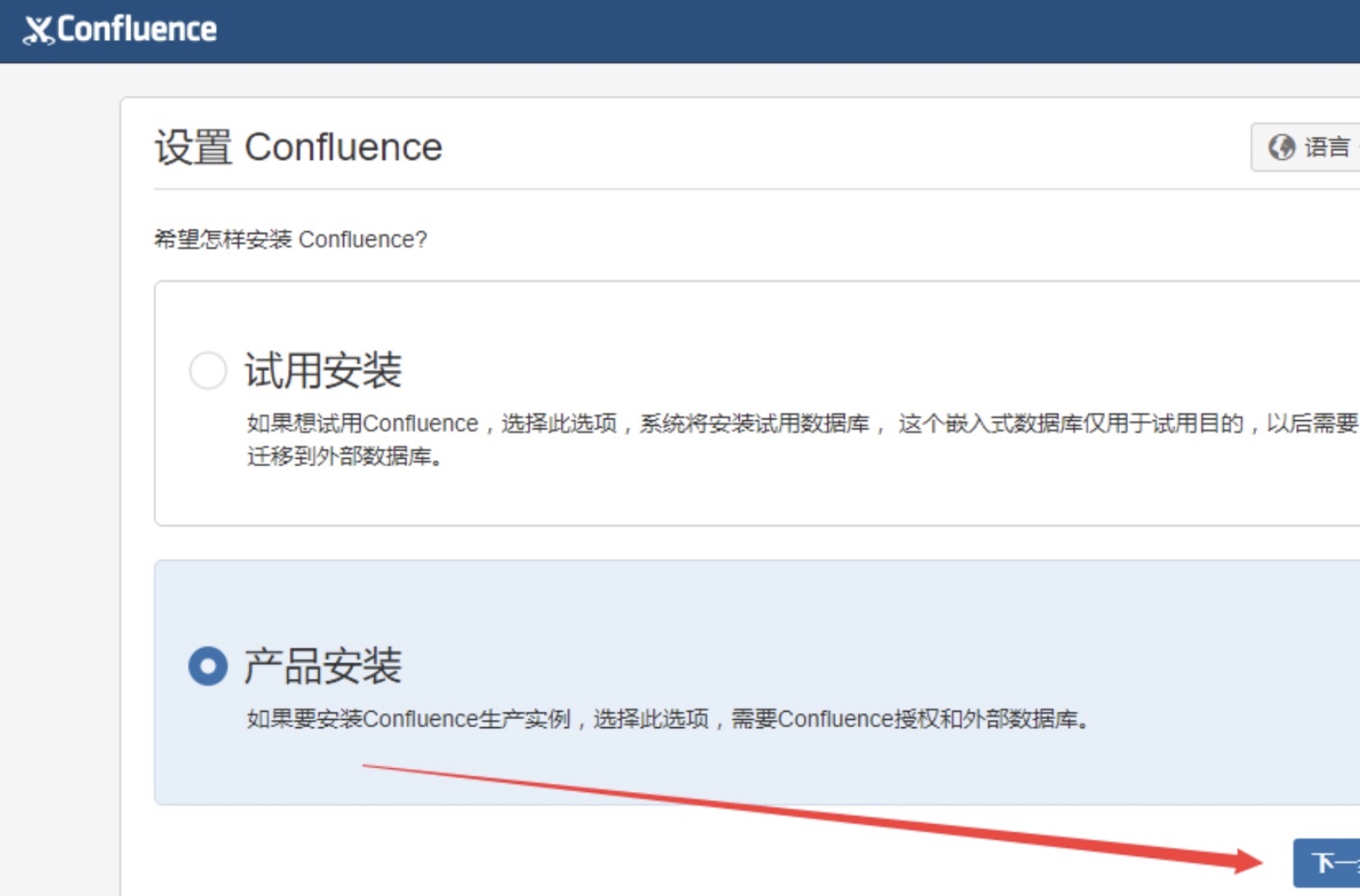
不要选择任何插件
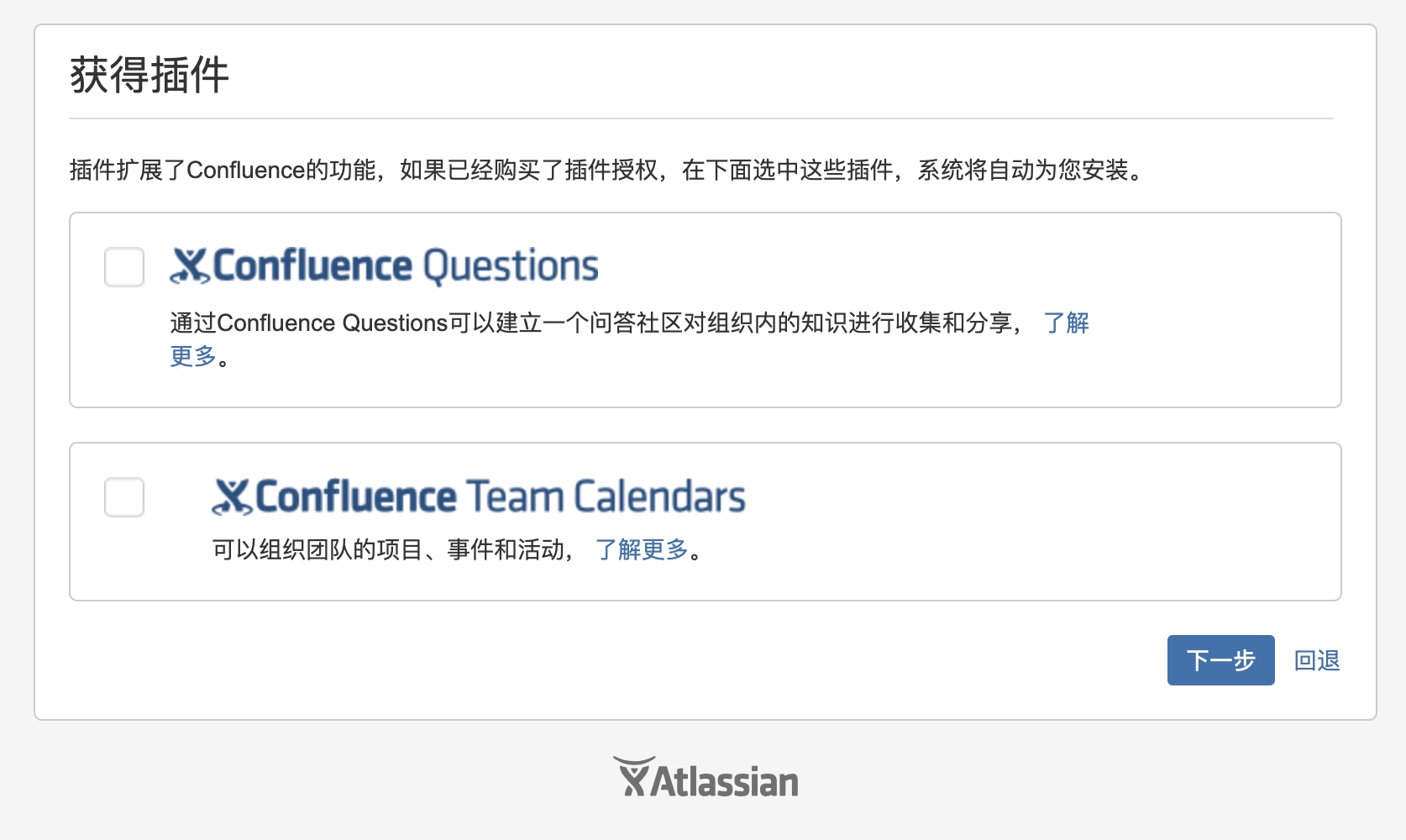
到这一步,记录服务器ID,不要关掉页面
停止confluence服务
sudo /etc/init.d/confluence stop
**a)**替换库文件
将confluence库文件/opt/atlassian/confluence/confluence/WEB-INF/lib/atlassian-extras-decoder-v2-3.2.jar通过scp拷贝到本地(可使用scp,rsync,ftp等)
下面在本地电脑操作:
将拷贝到本地的atlassian-extras-decoder-v2-3.2.jar改名为atlassian-extras-2.4.jar(因为破解工具只认这个版本的名称)
运行confluence_keygen.jar(mac里有java环境直接双击打开,win和linux可用java命令打开),填好ServerID,其他随便填。点击gen生成key并拷贝出来记录好。点击patch,选择刚重命名为atlassian-extras-2.4.jar的文件进行破解
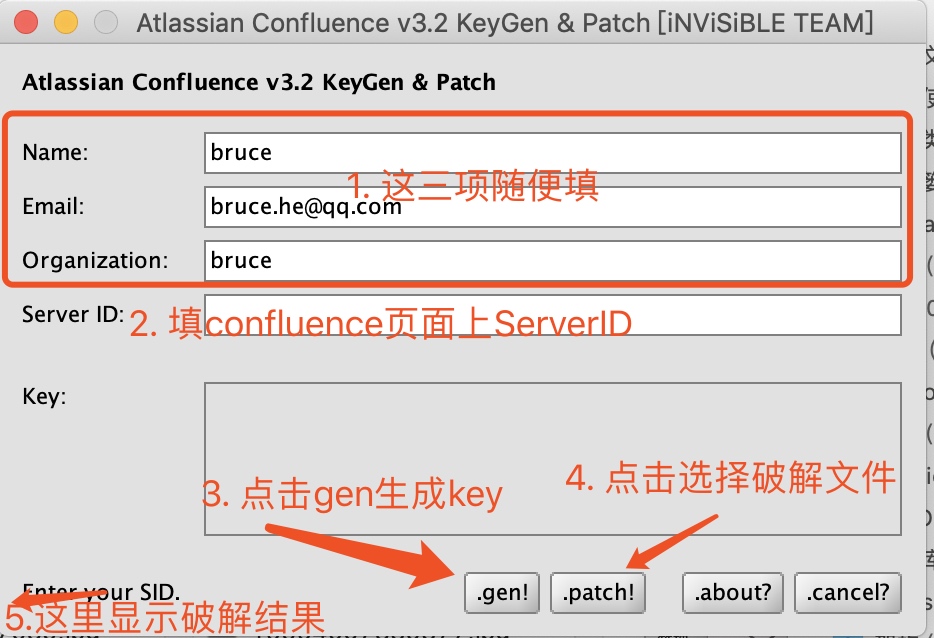
- 破解完成,将破解的文件atlassian-extras-2.4.jar回传到服务器
下面在服务器操作:
在服务器上将回传的atlassian-extras-2.4.jar重命名为atlassian-extras-decoder-v2-3.2.jar
mv atlassian-extras-2.4.jar atlassian-extras-decoder-v2-3.3.0.jar
然后覆盖回原路径:
cp -a atlassian-extras-decoder-v2-3.3.0.jar /opt/atlassian/confluence/confluence/WEB-INF/lib/
**b)**确保jira可访问mysql,将mysql-connector-java-5.1.39-bin.jar(放在破解工具目录)拷贝/opt/atlassian/confluence/lib/路径下
启动confluence服务
sudo /etc/init.d/confluence start
回到输入key的界面,输入上面记录的key,点击下一步
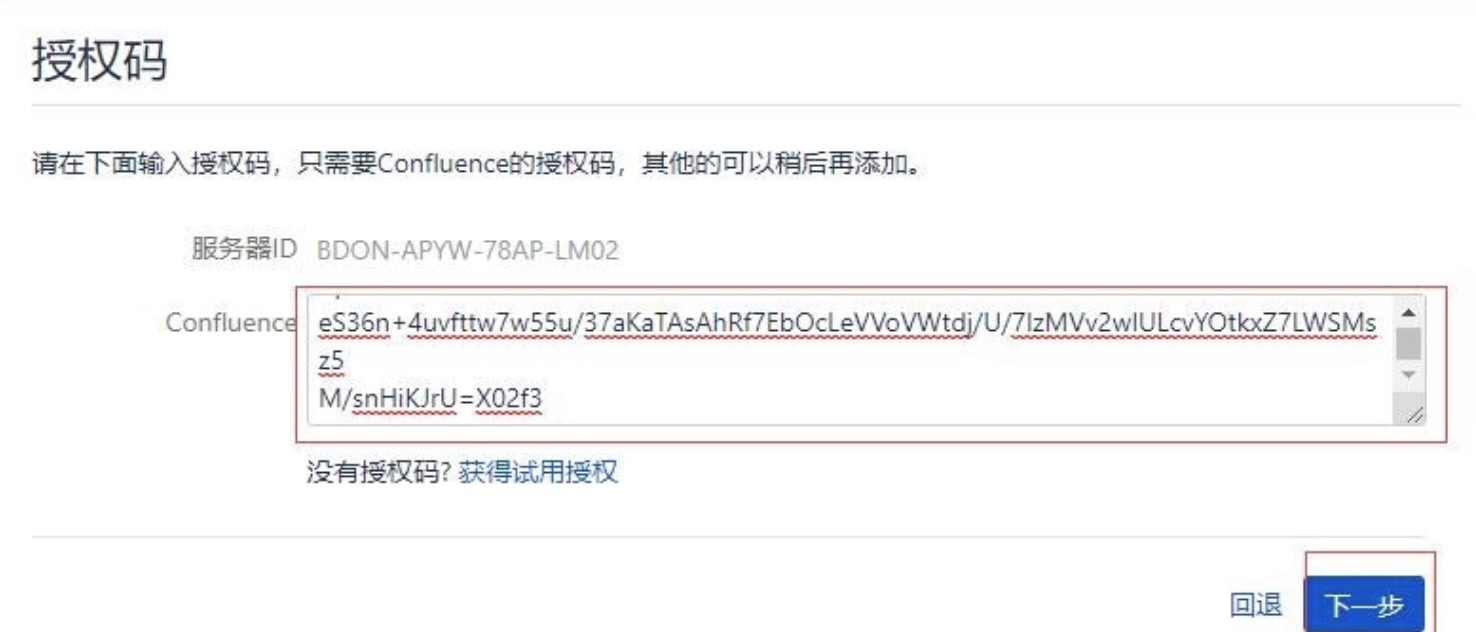
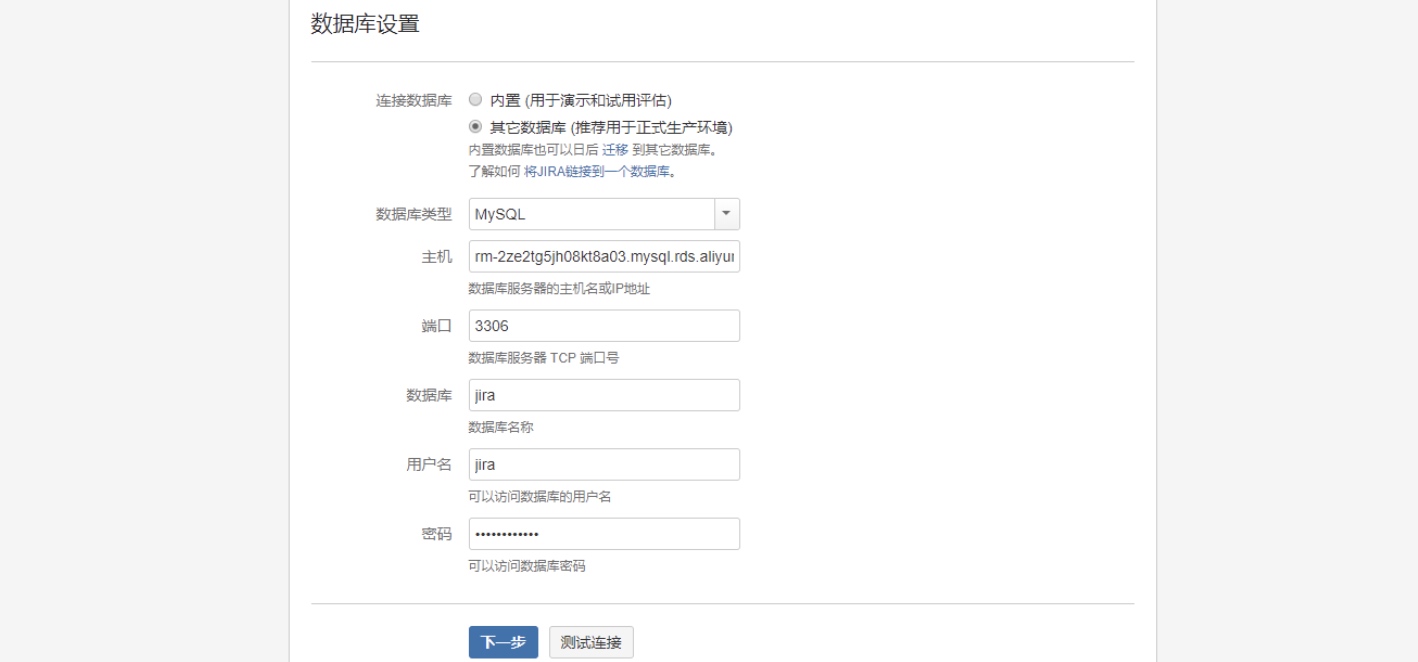
然后进行配置数据库:我选择的是我自己的数据库,这里需要对数据库进行一些配置。如果选择内置的话,就是使用嵌入式的数据库,不用配置什么东西,等一段(挺长的)时间,就好了。
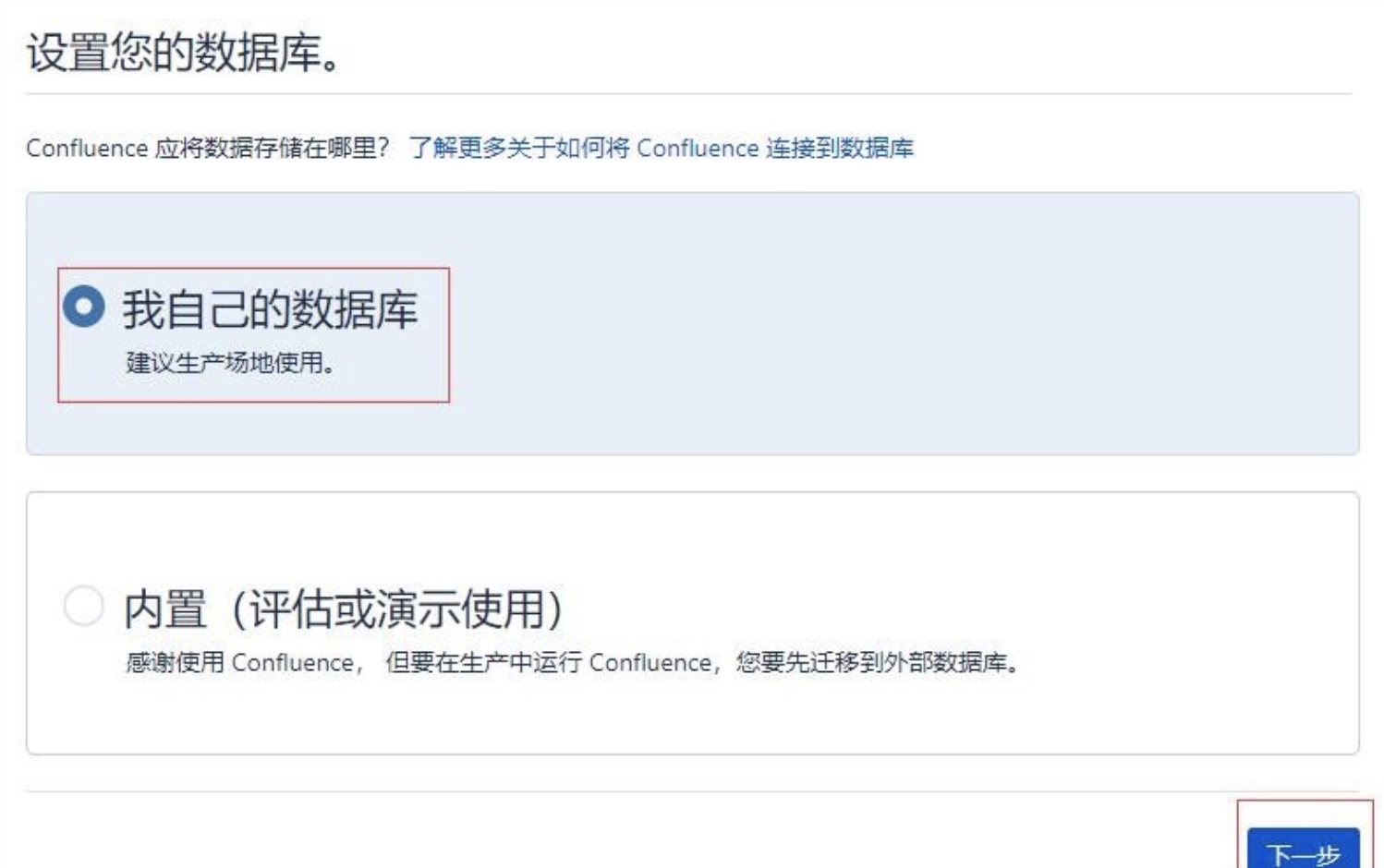
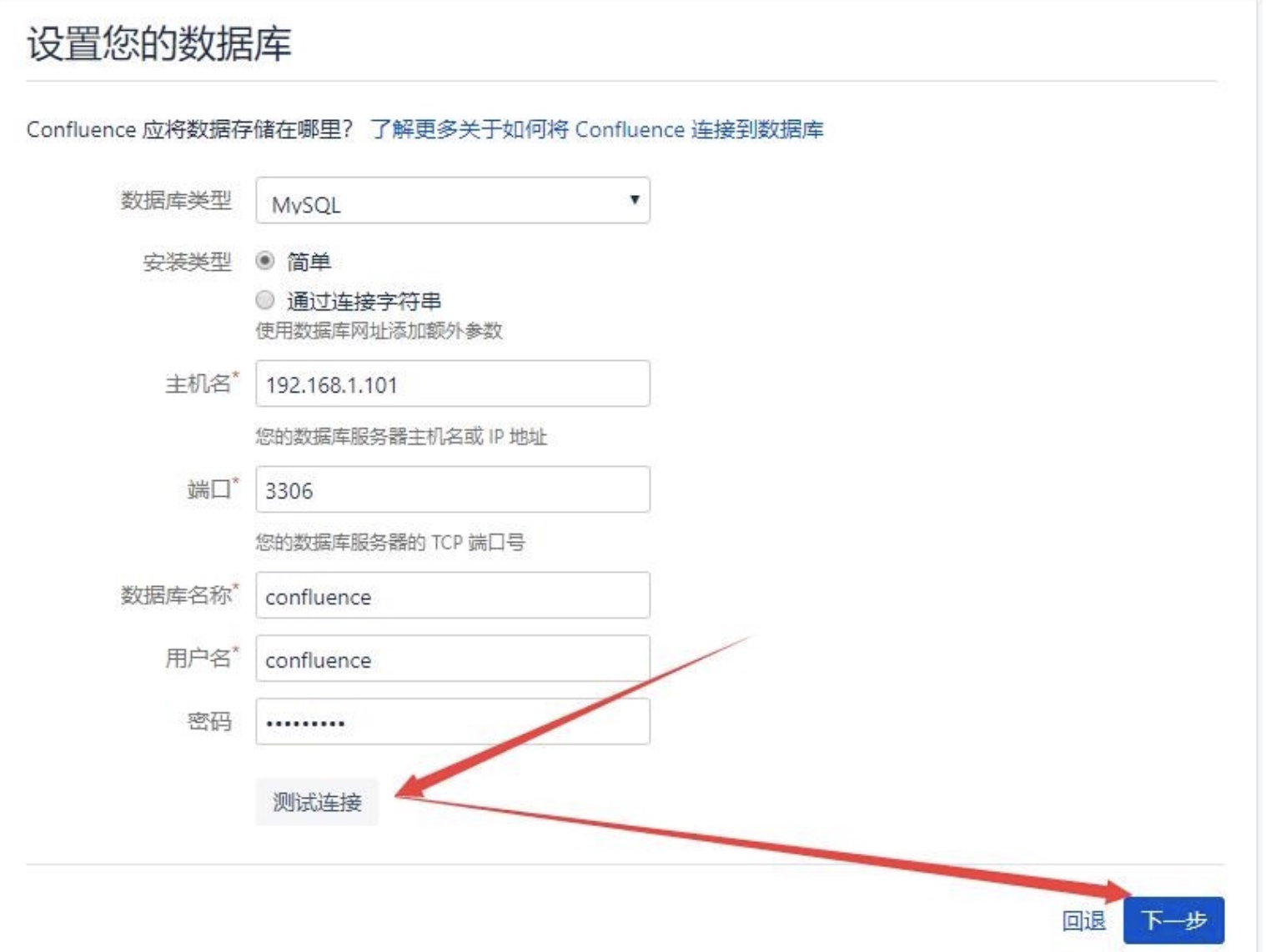
在测试成功后,下一步比较慢,需要往数据库写好多表。
注意:这一步因为用域名访问每次都报错,都必须删除重新安装,强烈建议用ip+port访问
连接数据库的配置文件:/var/atlassian/application-data/confluence/confluence.cfg.xml。
推荐使用示范站点,先熟悉Confluence,然后再自行进行设置
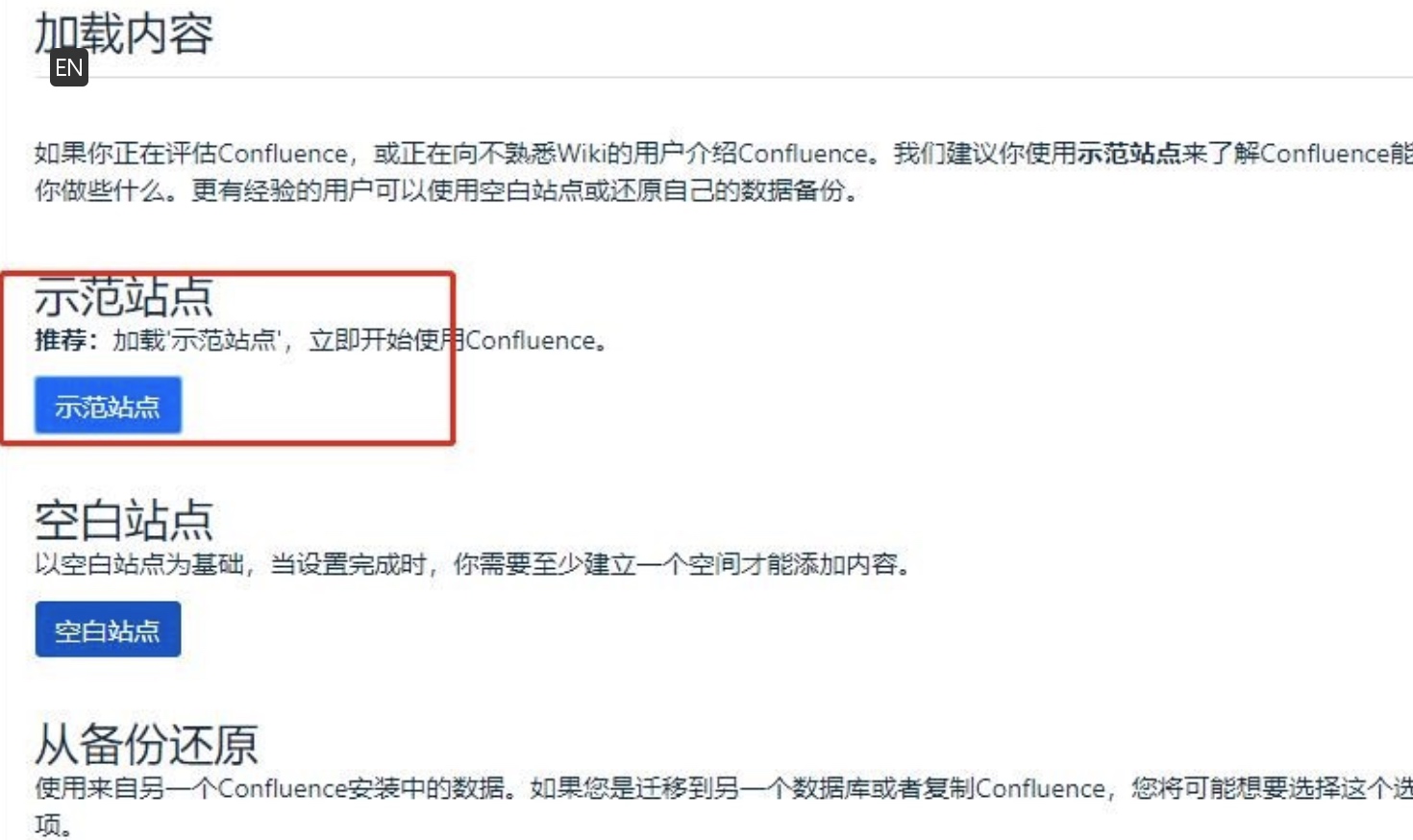
可以选择confluence中管理用户,也可选择jira链接,不过强烈建议选第一个,后面要链接再自己取加,
这个地方的坑一会在最后面记录。因为我们是基于jira用户,所以选择了第二个。
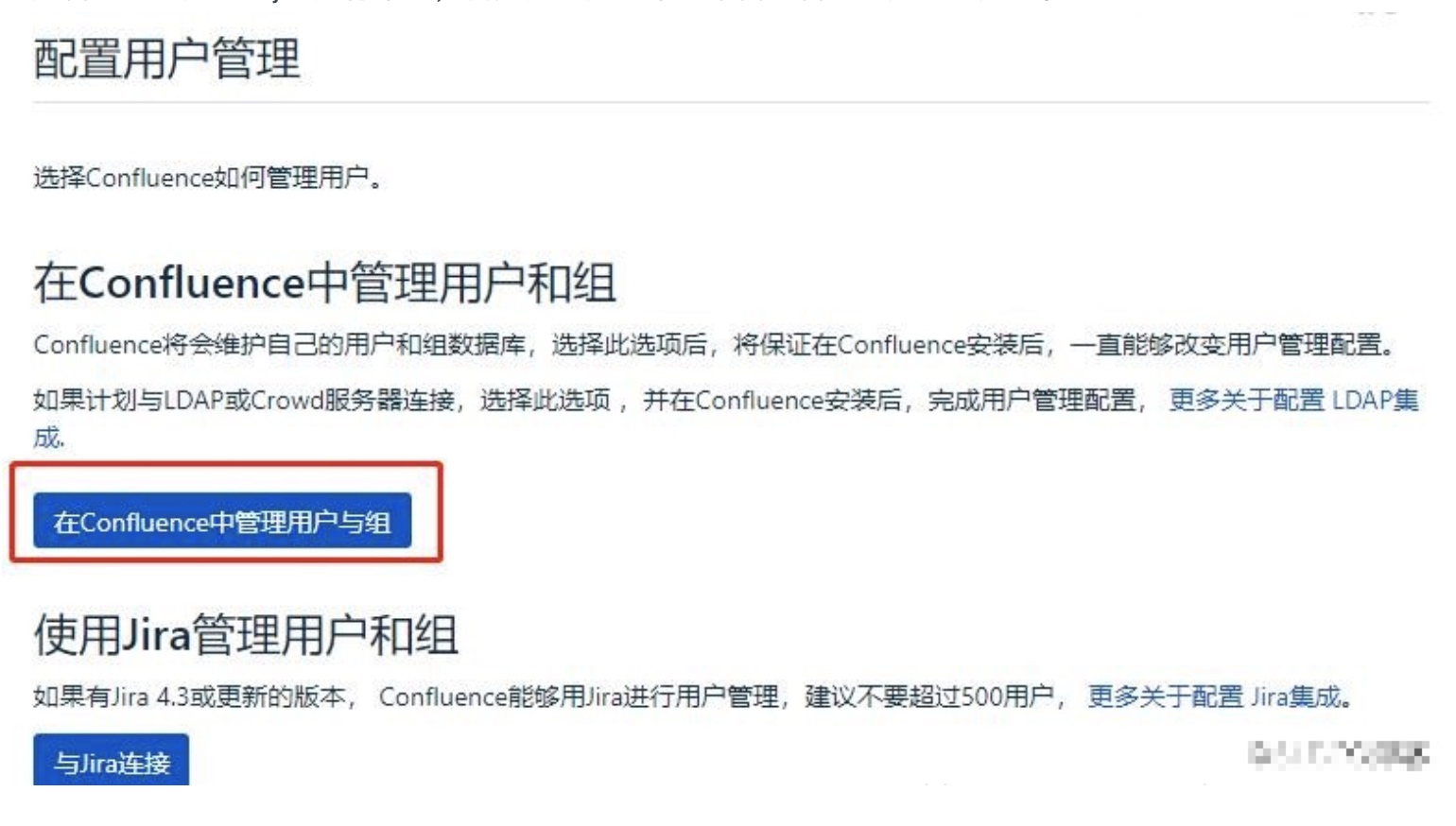
填完信息开始同步jira用户
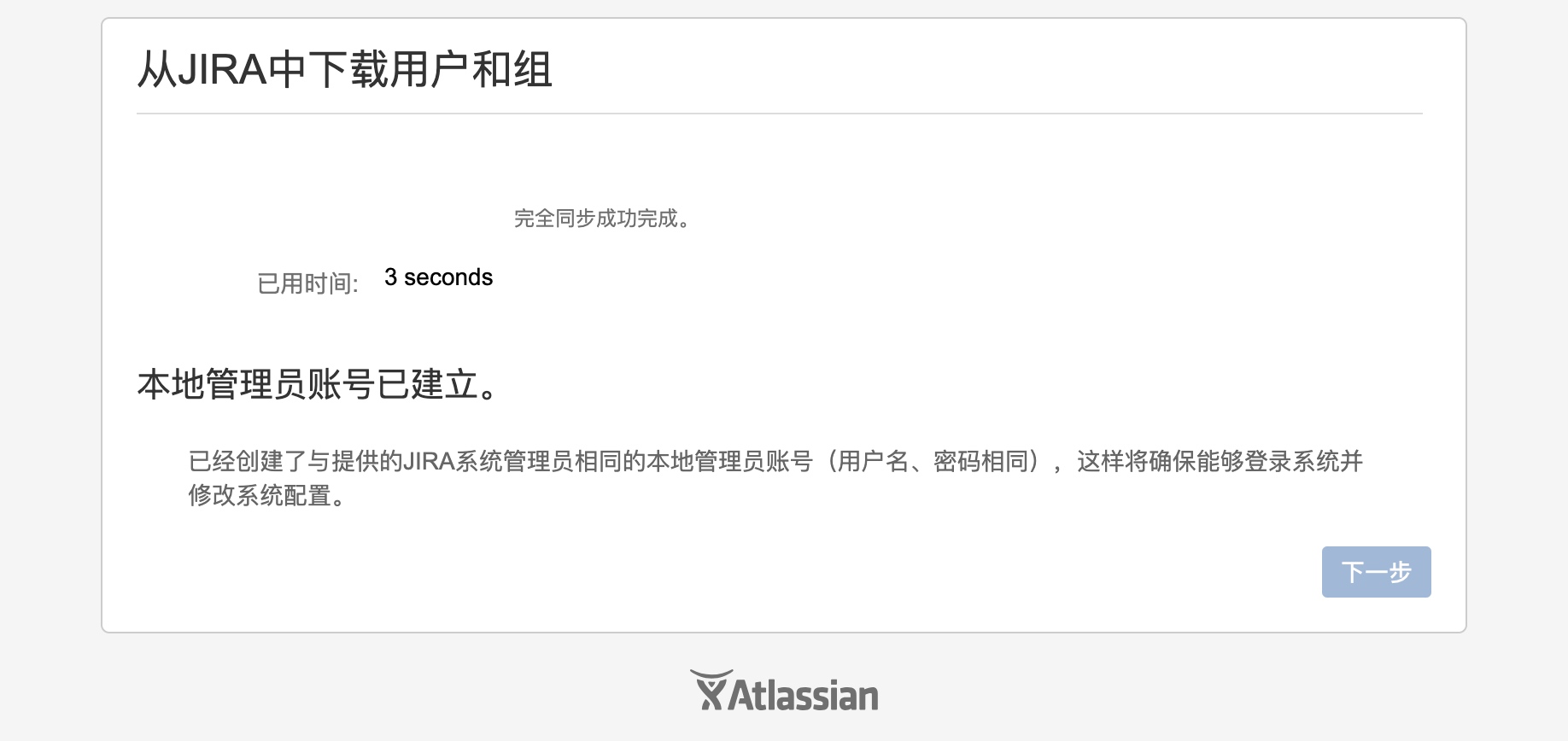
(我之前在这一步也失败过,所以我才说建议先创建内部账号。。。)
如果同步完成没报错,继续下一步配置完邮件(也可先跳过),选择语言,至此Jira的安装和破解完成。
可以打开http://ip:port/admin/license.action查看破解情况
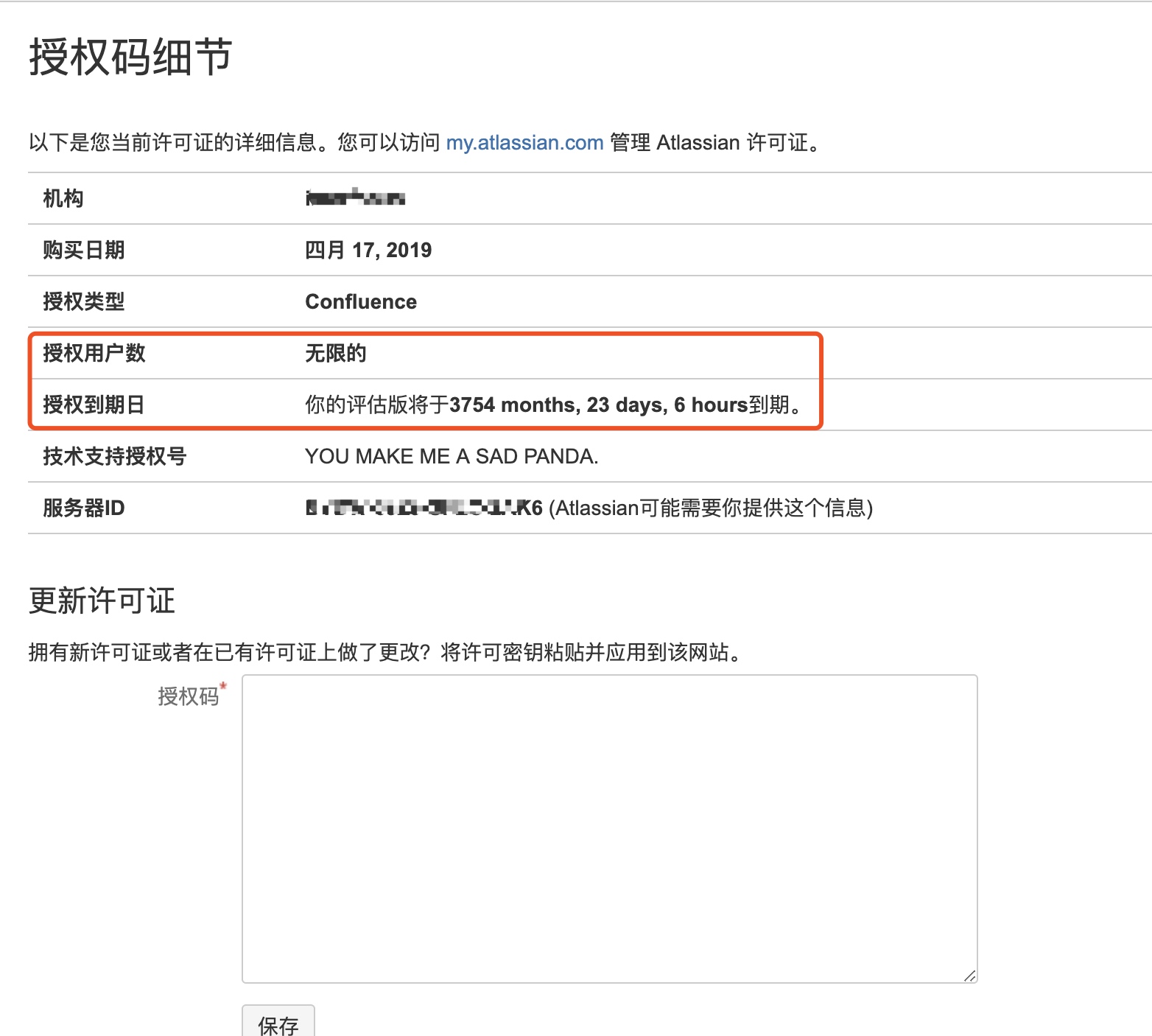
5.老机器confluence数据备份,新机器confluence数据恢复
**a)**管理员账号登录老机器confluence
点击右上角的"一般配置"-“每日备份管理”,如下图(默认配置):
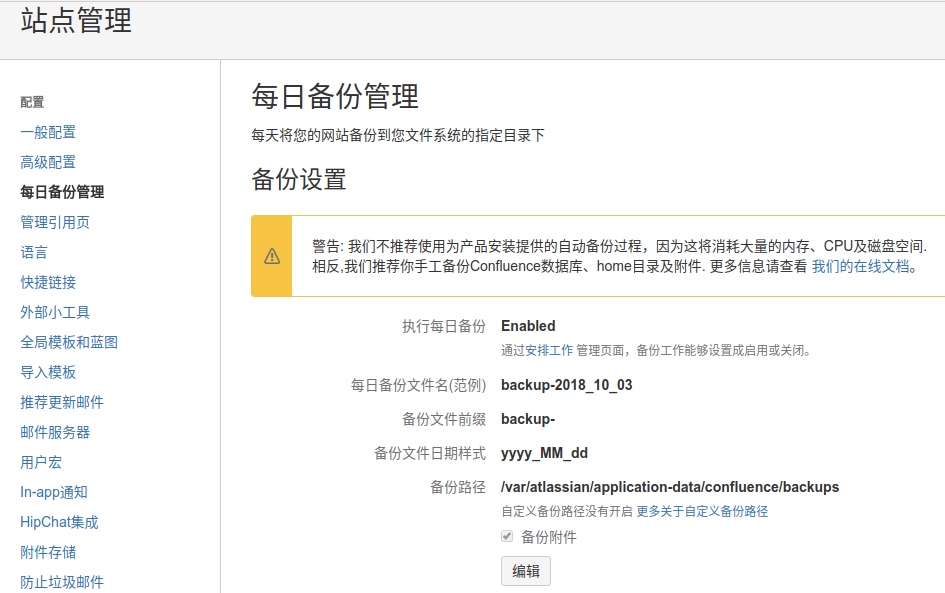
默认每天会自动备份一个zip打包的数据,存放在服务器的/var/atlassian/application-data/confluence/backups路径下。还可以点击"编辑"进行自定义。
默认每天2点左右都会整体备份一次!恢复或迁移的时候,可以直接用这里的zip打包数据进行恢复。除此之外,还可以点击"一般配置"-“备份与还原"里面的备份进行手动备份。
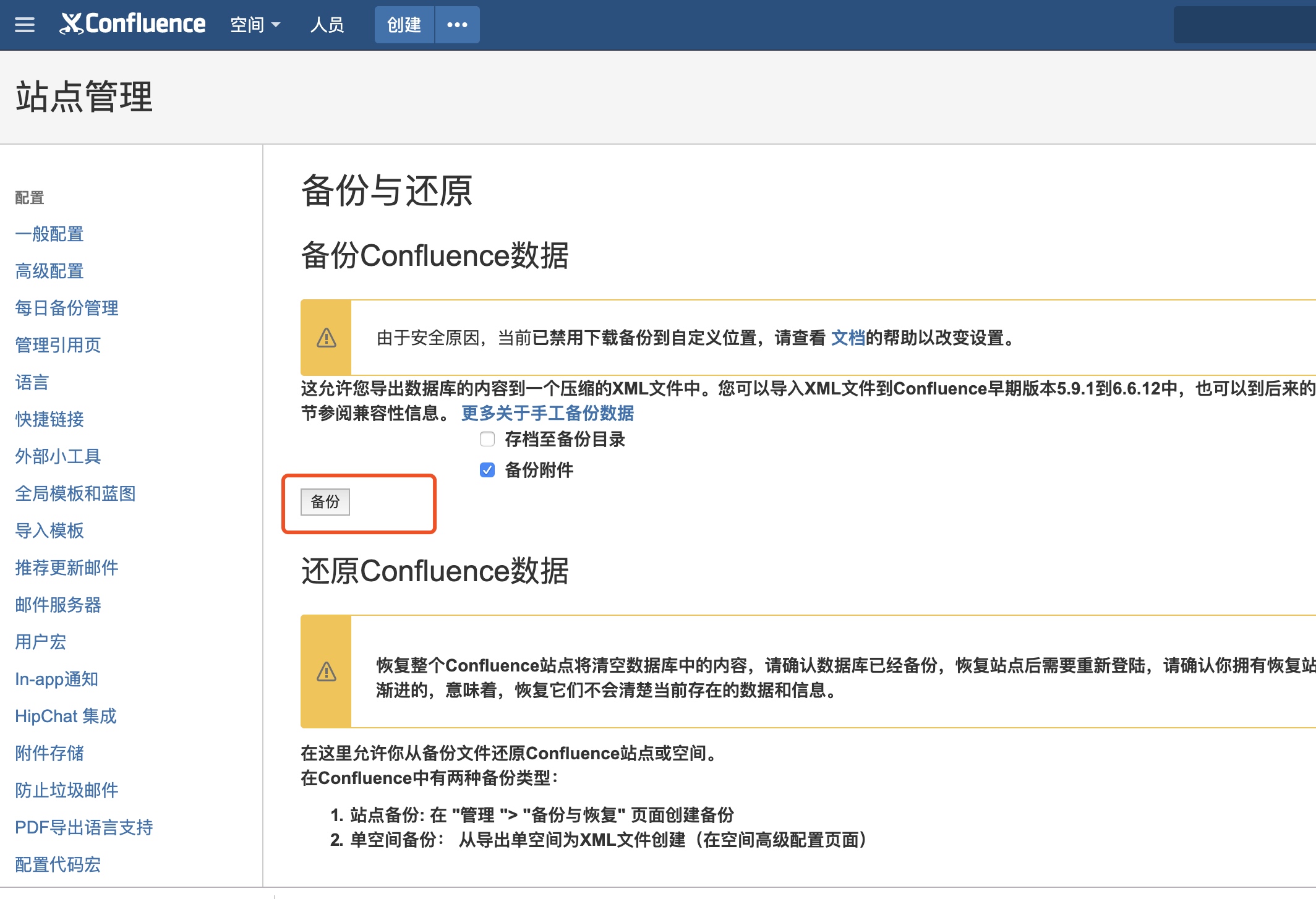
{% alert info %} 注意:最好将附件也从原机器备份过来。附件都保存在服务器的/var/atlassian/application-data/confluence/attachments路径下。 {% endalert %}
将confluence的备份文件confluence-backup.zip和attachments.zip文件拷贝到新机器。
**b)**管理员账号登录新机器confluence
停止confluence服务,将附件备份文件attachments.zip解压替换/var/atlassian/application-data/confluence/attachments目录(可先备份)。
将备份文件confluence-backup.zip拷贝到/var/atlassian/application-data/confluence/restore路径下。
启动confluence服务,点击"一般配置”-“备份与还原"里面的恢复进行数据恢复,
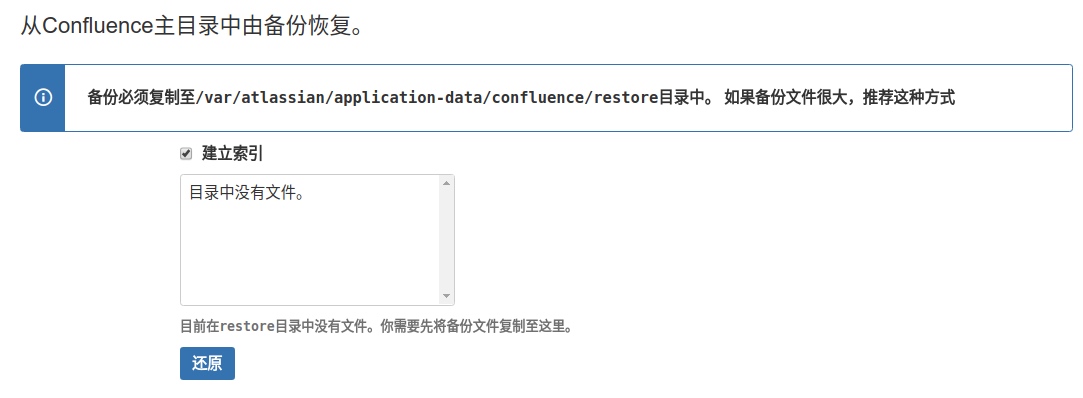
如果文件放到restore目录下了,会显示在图中列表里,选择文件,点击 [还原]开始恢复。
四、问题总结
1. confluence致命漏洞和修复
最近各大安全平台爆出Confluence Server远程代码执行漏洞
Atlassian 公司的 Confluence Server 和 Data Center 产品中使用的 widgetconnecter 组件 (版本<=3.1.3) 中存在服务器端模板注入 (SSTI) 漏洞。攻击者可以利用该漏洞实现对目标系统进行路径遍历攻击、服务端请求伪造 (SSRF)、远程代码执行 (RCE)。
攻击者可以通过构造恶意的 HTTP 请求参数,对目标系统实施(路径遍历、任意文件读取以及远程命令执行)攻击。该类攻击可导致目标系统中的敏感信息被泄露,以及执行攻击者构造的恶意代码。
尽快升级到confluence官方修复版,目前官方修复版本:
版本 6.6.12 及更高版本的 6.6.x. 版本 6.12.3 及更高版本的 6.12.x 版本 6.13.3 及更高版本的 6.13.x 版本 6.14.2 及更高版本
参考: 1.https://confluence.atlassian.com/doc/confluence-security-advisory-2019-03-20-966660264.html 2.https://www.chainnews.com/articles/426052160451.htm 3.http://news.ssssafe.com/archives/834 4.http://copyfuture.com/blogs-details/3a44938fcd7518cdda0f1390099382cd
2. confluence数据库字符乱码
在恢复数据时到一半就报错duplicate entry '???' for key xxx,去数据库查看,发现很多记录是?,查看数据库编码为latin(拉丁文),修改mysql5.7配置
vi /etc/mysql/mysql.conf.d/mysqld.cnf
在mysqld下增加字符相关配置,修改log的size,配置如下
#set character
symbolic-links=0
collation_server=utf8_unicode_ci
character_set_server=utf8
skip-character-set-client-handshake
transaction-isolation=READ-COMMITTED
key_buffer_size = 32M
max_allowed_packet = 128M
thread_stack = 192K
thread_cache_size = 8
innodb_log_file_size = 512M
重启mysql,再导入不会报错。
参考:https://confluence.atlassian.com/jirakb/health-check-database-collation-in-mysql-943951422.html
3. confluence账户体系
confluence包含两套账户体系:confluence内部的用户、外部链接的用户(jira,ldap等) confluence内部用户:创建、更新都只对confluence生效,目录属于Confluence Internal Directory。 外部链接的用户:和jira共用账户体系,通过应用程序链接授权和同步用户到confluence,在添加程序链接时可以设置单向同步还是双向同步。
强烈建议在confluence搭建时一定要先创建一个内部用户管理员账号,而且只有内部用户管理员才可以编辑非内部目录链接,编辑连接(http://host:port/plugins/servlet/embedded-crowd/directories/list)。
添加jira外部用户链接步骤:
- 在jira里添加[JIRA用户服务器],打开http://jira.xxxx.com/secure/admin/ConfigureCrowdServer.jspa,(修改url成你自己jira的域名)。添加一个新应用程序:
- 输入Confluence在访问Jira时将使用的应用程序名称和密码(可自己定义),
- 输入Confluence服务器的IP地址(如果和jira在同一台服务器,最好用内网ip)
- 保存。
- 在confluence里添加用户目录, 打开http://host:port/plugins/servlet/embedded-crowd/directories/list,(修改url成你自己confluece的域名)。添加一个用户目录:
- 选择类型(jira)
- 填应用名称,填服务器的URL(Jira服务器地址,如果和confluence在同一台服务器,建议填内网),第1步中设置的应用程序名称,密码
- 其他项看情况自己选择,点测试设置,通过后保存
参考: 1.https://confluence.atlassian.com/doc/connecting-to-crowd-or-jira-for-user-management-229838465.html#ConnectingtoCrowdorJIRAforUserManagement-ConnectingConfluencetoJIRAforUserManagement 2.https://www.cnblogs.com/kevingrace/p/5569932.html
4. confluence无法登录解决办法
遇到一个很尴尬的问题,confluence全部安装完成运行,也设置好了confluence内部用户管理员账号, 可还原备份数据后,新的内部管理员账号被删除,外部链接设置也被还原成老的配置,导致用内部管理员账号无法登录,用老账号也无法登录!
第一次选择了重装,到还原这一步又是同样的问题,最后去官网找到了解决方案,大致思路:
- 通过sql直接在数据库创建内部用户管理员账号
- 用内部管理员账号登录进去后修改jira外部用户链接配置
相关SQL:
#1.创建用户confluence-admin,密码admin
insert into cwd_user(id, user_name, lower_user_name, active, created_date, updated_date, first_name, lower_first_name, last_name, lower_last_name, display_name, lower_display_name, email_address, lower_email_address, directory_id, credential) values (1212121, 'confluence-admin', 'confluence-admin', 'T', '2009-11-26 17:42:08', '2009-11-26 17:42:08', 'A. D.', 'a. d.', 'Ministrator', 'ministrator', 'A. D. Ministrator', 'a. d. ministrator', '[email protected]', '[email protected]', (select id from cwd_directory where directory_name='Confluence Internal Directory'), 'x61Ey612Kl2gpFL56FT9weDnpSo4AV8j8+qx2AuTHdRyY036xxzTTrw10Wq3+4qQyB+XURPWx1ONxp3Y3pB37A==');
#2.添加映射关系
insert into user_mapping values ('2c9681954172cf560000000000000001', 'confluence-admin', 'confluence-admin');
#3.非必须步骤:创建组,这一步可以自己去数据库先看看,可能已经创建过了
insert into cwd_group(id, group_name, lower_group_name, active, local, created_date, updated_date, description, group_type, directory_id)
values ( '888888','confluence-administrators','confluence-administrators','T','F','2011-03-21 12:20:29','2011-03-21 12:20:29',NULL,'GROUP',(select id from cwd_directory where directory_name='Confluence Internal Directory'));
insert into cwd_group(id, group_name, lower_group_name, active, local, created_date, updated_date, description, group_type, directory_id)
values ( '999999','confluence-users','confluence-users','T','F','2011-03-21 12:20:29','2011-03-21 12:20:29',NULL,'GROUP',(select id from cwd_directory where directory_name='Confluence Internal Directory'));
#4.将用户添加到组confluence-users和confluence-administrators
insert into cwd_membership (id, parent_id, child_user_id) values (163841, (select id from cwd_group where group_name='confluence-users' and directory_id=(select id from cwd_directory where directory_name='Confluence Internal Directory')), 1212121);
insert into cwd_membership (id, parent_id, child_user_id) values (163842, (select id from cwd_group where group_name='confluence-administrators' and directory_id=(select id from cwd_directory where directory_name='Confluence Internal Directory')), 1212121);
#5.验证一下是否添加成功
select u.id, u.user_name, u.active from cwd_user u
join cwd_membership m on u.id=m.child_user_id join cwd_group g on m.parent_id=g.id join cwd_directory d on d.id=g.directory_id
where g.group_name = 'confluence-administrators' and d.directory_name='Confluence Internal Directory';
#查目录
select d.id, d.directory_name, m.list_index from cwd_directory d join cwd_app_dir_mapping m on d.id=m.directory_id;
select id, directory_name, active from cwd_directory where id = 98306;
详细步骤参考官网: