消息队列中间件选型
“消息队列”是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它。
一.消息队列是什么
维基百科的解释:
消息队列(英语:Message queue)是一种进程间通信或同一进程的不同线程间的通信方式,软件的贮列用来处理一系列的输入,通常是来自用户。消息队列提供了异步的通信协议,每一个贮列中的纪录包含详细说明的数据,包含发生的时间,输入设备的种类,以及特定的输入参数,也就是说:消息的发送者和接收者不需要同时与消息队列互交。消息会保存在队列中,直到接收者取回它。 ——维基百科
解释比较官方,来看一个最简单的架构模型:
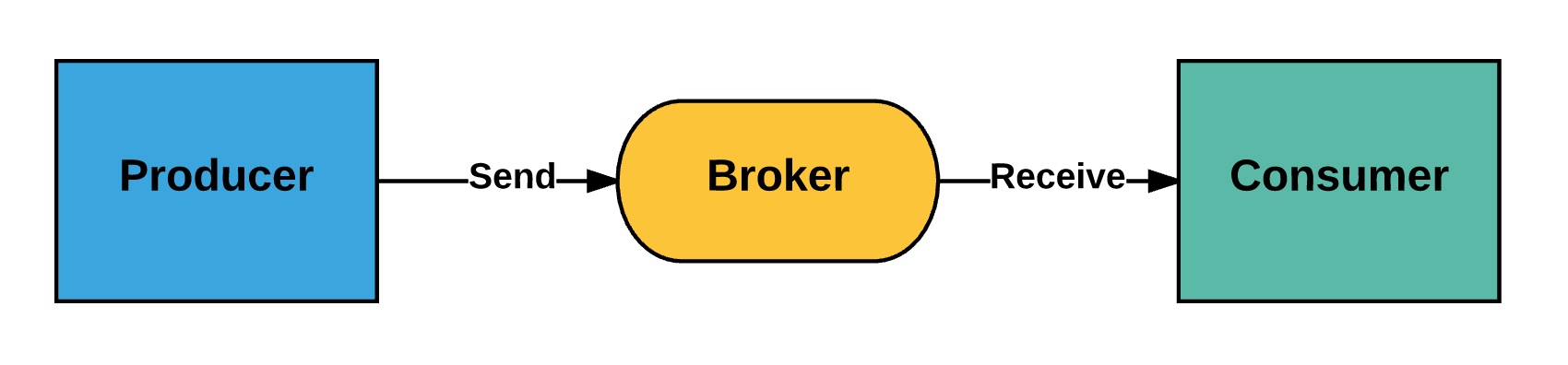
- Producer:消息生产者,负责产生和发送消息到Broker;
- Broker:消息处理中心,负责消息存储、确认、重试等,一般其中会包含多个queue;
- Consumer:消息消费者,负责从 Broker 中获取消息,并进行相应处理;
消息队列是分布式系统中重要组件,使用消息队列主要是通过异步处理提高系统性能和削峰、降低系统耦合性。
下面用一个故事来理解消息队列:
小Y是攻城狮,有一天产品经理告诉他需要实现这样一个需求:“用户下单成功,给用户发送一封确认邮件”.小Y快速确认了需求,很简单嘛,加几行代码就搞定!如是在下单后调用发送邮件代码,经过本地和alpha测试,功能顺利上线。
正常运行了几天,产品经理找到小Y说观察监控数据,发现下单处理时间过长影响了转化率,小Y思考了一下,原来发邮件代码是放在下单完成代码后单线程同步阻塞的方式执行,确实有问题,于是新起了一个线程发邮件,测试通过后立即上线,下单感觉确实更顺畅了。
可是没过多久客服收到很多用户反馈没收到邮件,产品经理和小Y一起熬夜分析想办法,最后找到负责开发邮件模块的同事,负责邮件的同事说:“不用搞那么复杂,我给你提供一个类似邮局信箱的东西,你往这信箱里写上你要发送的消息,以及我们约定的地址。之后你就不用再操心了,我们自然能从约定的地址中取得消息,进行邮件的相应操作”。小Y快速按照邮件同事的建议修改了代码,并测试重新上线。
小Y后来才知道这个就是消息队列,你只需要将你想发送的消息发送到队列里,不用知道具体服务在哪,怎么执行,对应的服务自然能监听到你的发送的消息并获取过来执行。
后来其他业务也把邮件发送更换成这种方式,随着消息量增多,大量消息堆积,需要增加更多消费者来处理队列里的消息,于是便有了分布式消息处理
二.为什么要用消息队列
当系统出现"生产"和"消费"的速度和稳定性不一致时,就需要消息队列,正是这个中间层弥合双方的差异。使用消息队列主要三个好处(六字):解耦、异步、削峰。
1.解耦
场景:A更新数据,通知B,C更新,D等待接入。
传统架构:
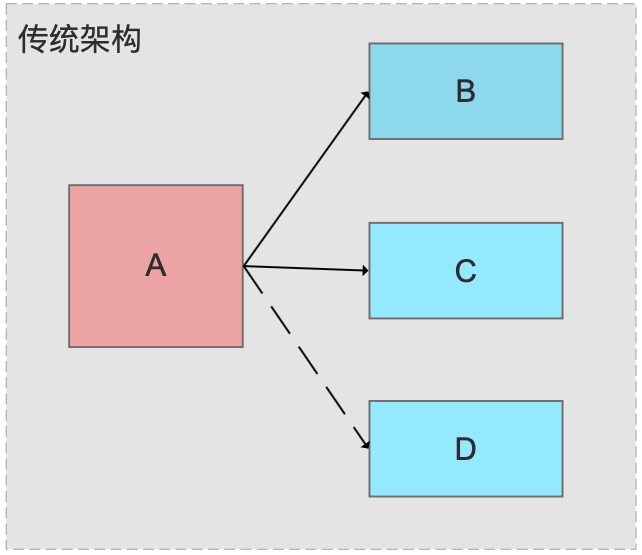
传统架构下,A更新数据后分别调用B,C系统API,将更新的数据传过去,这种结构有下面的问题:(1)耦合性太强 (2)B,C系统故障,无法正确接收更新数据 (3)如果有D再接入,A又需要配合修改代码
引入消息队列中间件架构:
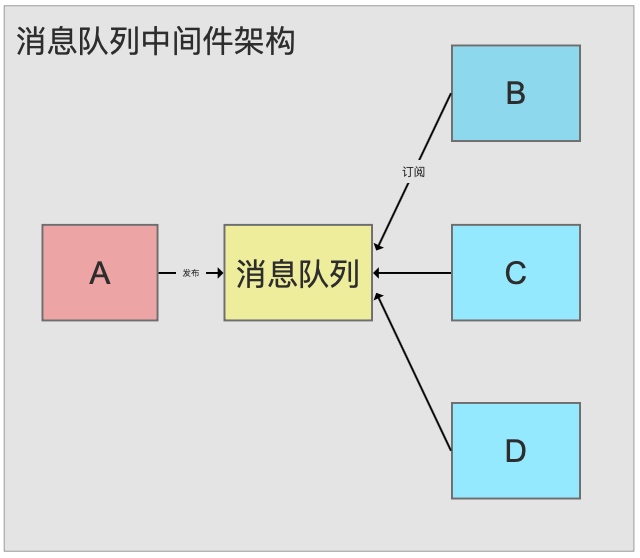
引入消息队列中间件的架构后,如果A更新了数据,只需要将消息发布到消息队列,B,C只要从消息队列订阅这条消息,D接入也只需自己去订阅,完全无需A做任何改动。
消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响。
2.异步
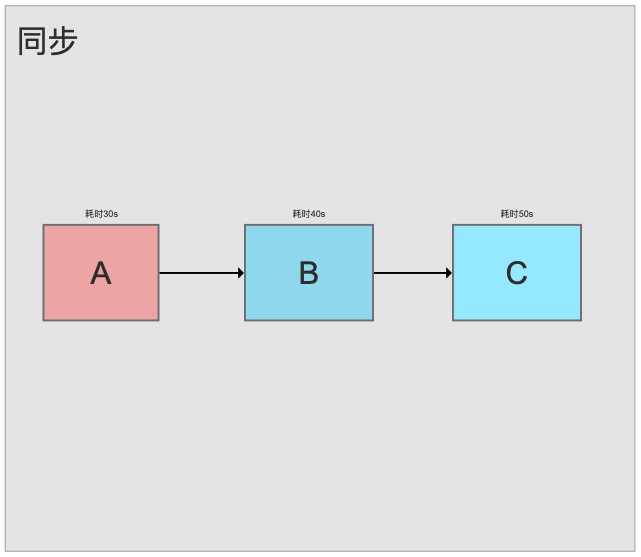
同步模式下,整个任务完成要耗时120s
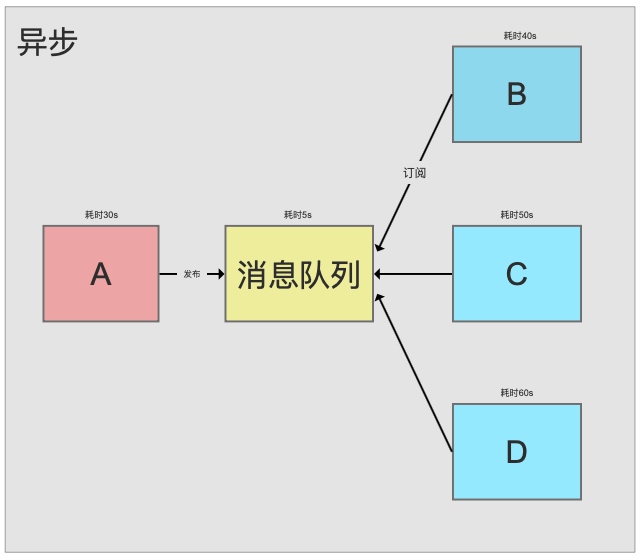
消息队列异步模式下耗时35s,B,C异步运行。 异步处理主要目的是减少请求响应时间,实现非核心流程异步化,提高系统响应性能。
3.削峰
**场景1:**A系统有10000条数据更新,需要发送给B,C系统
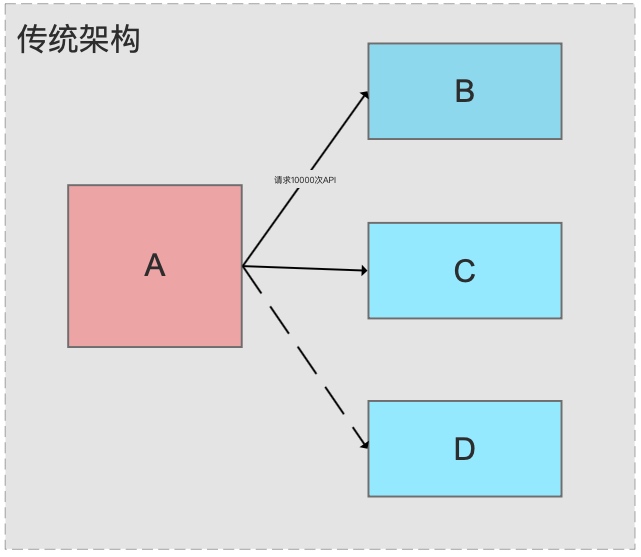
传统架构下,A系统调用B,C系统的接口发消息过去,B,C系统处理能力A是无法预估的,可能B,C系统流量洪峰,最后导致系统崩溃。
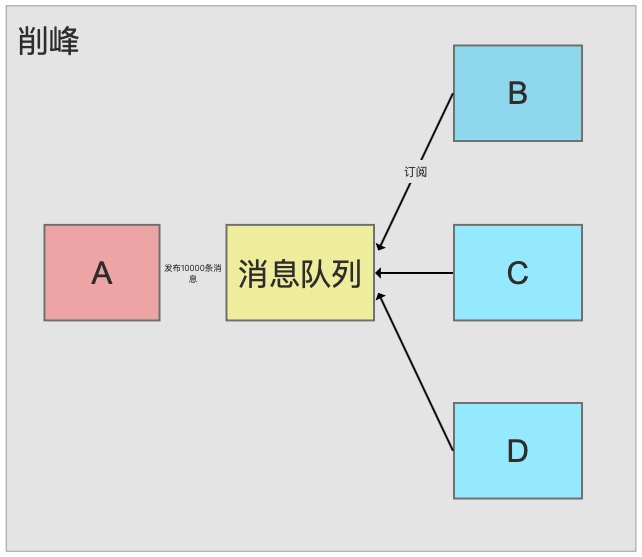
消息队列架构下,系统BCD可以按照自己处理能力消费队列里的消息,在流量高峰期短暂积压是被允许的。
**场景2:**每天0:00到12:00,A系统风平浪静,每秒并发请求数量50个.结果每次一到12:00~13:00,每秒并发请求数量突然会暴增到5k+条,A系统是直连mysql,假设mysql最大并发处理能力每秒2k,很明显这个时候mysql会被打死,导致系统崩溃,停止服务。但一过高峰期每秒请求量可能就50个,对系统毫无压力。如果使用消息队列,高峰期5k+每秒的请求先写入到消息队列,A系统每秒最多处理2k个请求,不超过自己最大处理能力,这样高峰期不会崩溃,由于这时消息数入大于出,就形成了高峰期短暂积压(百万消息堆积),高峰期过后,每秒就50个请求,A系统还是按照每秒2k处理,多出来的能力可以快速处理高峰期积压。
三.使用消息队列带来的问题
考虑在项目引入一项新技术,除了知道这项技术的优点,更重要是对弊端的了解,如果都没考虑过,就把技术引入,就给项目带来了潜在风险。上面我们列了消息队列的有点,来一起看看它的缺点。
1.降低系统可用性
系统可用性在某种程度上降低,在加入MQ之前,不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后就需要去考虑.
2.增加系统复杂度
原来两个系统简单直接调API相互通讯,加入MQ后,消息传递链路加长,延时会增加,要考虑消息传递的可靠性(消息丢失怎么处理?),消息不被重复消费,数据一致性等问题。
四.什么时候用消息队列
1. 数据驱动的任务依赖
什么是任务依赖?举个例子:电商公司需要跑拣货单,在这之前可能需要同步订单,更新库存等,这些任务之间就存在一定依赖关系。下面是一个任务依赖示范图:
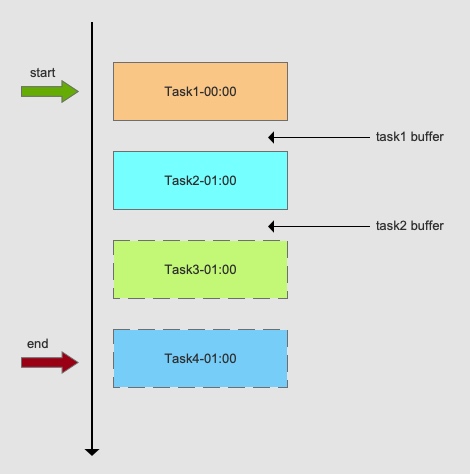
(1) Task3需要Task2输出作为输入 (2) Task2需要Task1输出作为输入
Task1,Task2,Task3就是任务依赖关系,必须先按照顺序Task1->Task2->Task3执行。类似的需求很多时候我们都是用cron人工排时间实现(预估每个task执行时间,然后留合适的间隔时间buffer): (1) Task1 00:00执行,执行50分钟,Task1的buffer时间10分钟 (2) Task2 01:00执行,执行40分钟,Task2的buffer时间20分钟 (3) Task3 02:00执行,执行时间30分钟,依次类推
这种方式可能遇到的问题:
(1) 如果一个Task执行超出预期时间(例如随着样本数据增加,需要更长时间计算),后面的Task不清楚前面是否成功,此时需要手动重跑或调整时间安排。 (2) 需要预留很多buffer,总任务执行时间很长,后置任务不能再前置任务完成立即执行 (3) 如果一个任务被多个任务依赖,定时任务提现不出来,被改动后,依赖的任务容易出错 (4) 一个任务的时间调整,将有多个任务执行时间调整
加入MQ优化后:
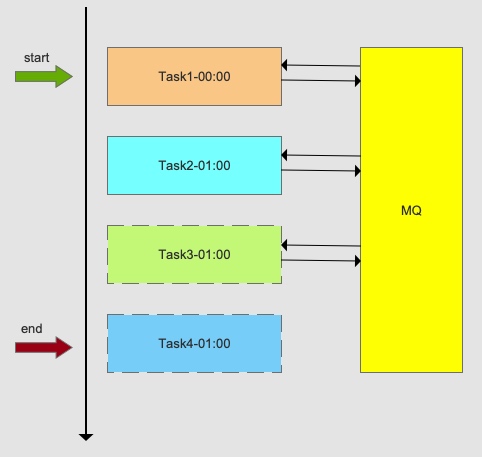
(1)task1执行完成,发送消息X1到MQ,不需要预留buffer时间,上游执行完,立即发起通知 (2)task2订阅消息X1,收到消息后第一时间启动执行,执行完成发送消息X2,多个任务依赖只需要订阅相关消息即可,不关心依赖任务执行时间。 (3)task3以此类推。
注意MQ只用来传递上下游执行完成的消息,不传递真正的输入输出数据。
2. 上游不关心下游执行结果
上游任务完成不关心下游执行结果,例如下完订单给用户发送邮件,下单和发送邮件是两个任务,下完单后发消息到MQ,发送邮件任务收到消息开始发送邮件,至于发送成功还是失败,下单这个任务已经不关心。
3. 异步返回执行时间长
任务A执行时间长,完成后发消息给MQ,消息订阅方收到结果。例如微信付款流程,用户发起付款调用微信付款服务,是否是立即付款不确定,但发起付款方很在乎支付结果,这时可以让微信服务回调接口将支付结果发到MQ,发起方订阅MQ消息,这样微信付款完成发起方立即就收到结果通知。
五.如何选择消息队列
上面从优缺点,使用场景方面介绍了消息队列,我们可以看到消息队列是一个复杂的架构,引入它有很多好处,但也得针对它带来的问题做各种额外技术方案和架构来规避。市面上消息队列款式比较多,那么怎么选择呢?我找了目前使用较多的几个消息队列做对比。
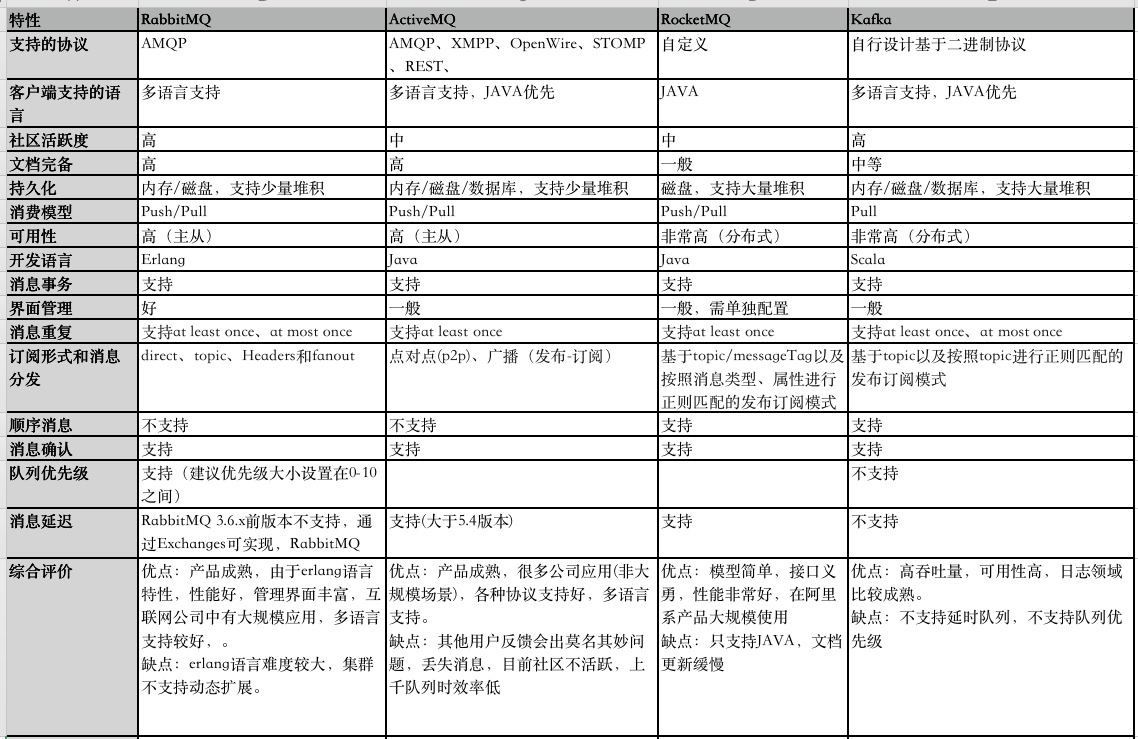
任何脱离业务实际的技术选型就是耍流氓,可根据团队技术栈,业务规模做出合适选择。对于中小型互联网公司,RabbitMQ是不错的选择,管理简单,社区活跃,文档多,兼容语言多。kafaka更多是给大数据领域准备。
相关文章: 消息队列-RabbitMQ